����
FFT�������źŴ�������һ�ַdz���Ҫ���㷨�����൱����������Ź㷺��Ӧ�á�FFT��������ΪFFT�㷨��Ӳ��ʵ�֣���ʵ����ҲԽ��Խ�ܵ���ҵ����ӡ�Ŀǰ����FPGAоƬ���Ҷ��Ƴ��˴��ж���FFTIP�˵IJ�Ʒ�����������ݸ�ʽ������������Ķ�̬��Χ��С������������Ȳ��ߣ���һЩ����Ҫ��ϸߵIJ�Ʒ����ʹ�á�������ڼ��������Ժ���չ�Ե�ͬʱ���1024���Զ����ʽ��24λ����FFT�źŴ����������,���øĽ��ĵ������㵥Ԫ,��СϵͳӲ������,������ϵͳ����;�����˸���ӷ���/�������ͳ˷�����һ����ˮʵ�ַ�ʽ,�����ϵͳ�������ٶȡ�ͬʱ����ƿ��Է������չ�ɿ�����һ2N��FFT����ĸ��ٸ���FFT�ˡ�
1 �㷨��ѡ��
���FFT�����ٶȵ��ĸ���Ҫ����;���Dz�����ˮ�߽ṹ���������㡢���Ӵ�������Ŀ�����㷨�ṹ����ȷ���㷨�л���ʱ��Ӧ�ۺϿ���FFT�����ٶȡ��㷨��������FPGA�Ľṹ�ص��ʵ���㷨��Ӳ����Դռ�õ����ء�
һ����2�����㷨��1�����˺�2��������ɡ���һ����4�����㷨����3�����˺�8�����ӣ���Ȼ��4�����������ٶ��ǻ�2��������2�������ǻ�4�����㷨ռ����Դ�ǻ�2��������ռ����Դ2���ࡣ�ۺϿ��ǣ�������ѡ�û�2����Ĵ������ṹ��ͼ1��ʾ��
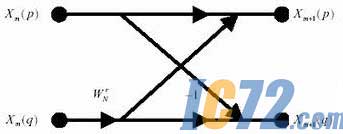
ͼ1��2�������㵥Ԫ�ṹ
2 ������ѡ��
FFT��������ɵ����������Ҫ�ǣ��������㡢���ݴ洢����������/�����ʽת����ʵ��FFT��������Ҫռ��FPGA��Ӳ����Դ��Ҫ������Block RAMs���龲̬�洢������MULT18X18s���˷�ģ�飩�ʹ���Slices��Xilinx��˾������Virtex2оƬXCV1000��һ��100���ż������ģ���ɵ�·оƬ��Ƭ����Դ�ḻ��������5120��Slice��40��MULT18X18s��720KbitRAM�洢����8������ʱ�ӹ���ģ��ȡ���оƬ����Դ�����ʺϽ��и�����������ݴ洢���������ԣ���ʵ�ʹ����У�ѡ��FPGA����XCV1000��ʵ��FFT��������
3 FFT�������ṹ
�����е�FFT�źŴ������Ľṹ��ͼ2��ʾ����ͼ2�п��Կ�����FFT����������:�������㵥Ԫ����ת����ROM����������RAM���������RAM��ַͬ����RAM������������ַ������������������
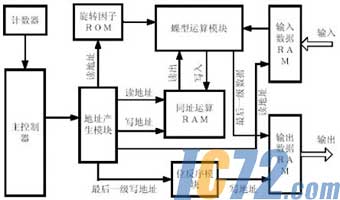
ͼ2 FFT �������ṹͼ
3.1 ����������㵥
3.1.1�Զ��Ƹ������ݸ�ʽ
ʵ�ֱ������ʽ����ѹ��������Ҫռ��FPGAƬ��̫����Դ��Ϊ�˼�����Դռ�ã�������ѡ��FPGA�������ص㣬�������ڲ������Զ��Ƶĸ������ݸ�ʽ���Զ��Ƹ���������24-bit��ʾ��bit23�Ƿ���λ����s��ʾ��bit22��bit17��6-bitָ��λ����e��ʾ��Bit16��bit��17-bitβ��λ����f��ʾ����������ֵv��ʾΪ��
V=(-1)s2(e-31)(1.f) ��1��
3.1.2����ӷ����ĸĽ��㷨
FFT��������������ԭ����ͼ��ͼ1��ʾ��������������ʵ�����鲿չ���У�
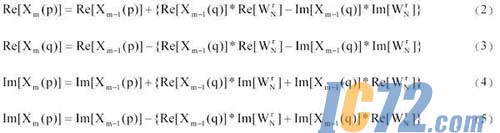
��ʽ��2������3������4������5���ɿ���������������������ʵ�����鲿����������ʵ����ӵõ�����Ӳ��ʵ�ֵ�������ʱ������������ͬʱ��ӷ������Լ��ټӷ���ˮʱ�䣬���ҹ���ǰ��0�ж����ģ�飬������Ӳ��ʵ�ֵ������㵥Ԫ����Դռ�á�
�������������ͨ�����²�������ɣ�
����������������Ƚ����������Ľ����С��ѡ�����Ľ���Ea���������Ľ�������������С�Ľ���������γɽײ�Ea-Eb=d1 Ea-Ec=d2 ��6��
���������룺�����������С�ĸ�����β���ֱ���Ӧ��������d1��d2λ��ʹ����λ�����������������ͬ��ָ����
��������Чλ���/�������ݷ�����ɶԽ״����������β������ӻ������
������ǰ��0���ж������ݽ���ж�ǰ��0����������ǰ��0���������б��������������λ��
�������������Ӻ�Ľ�����й������������Ӻ�Ľ��ת��Ϊ�ڲ��Զ��Ƶĸ������ݸ�ʽ��
3.1.3����˷���
����˷����Ľṹ��ԱȽϼ���Ҫ�����¼������裺
������������ӣ������������Ľ��벿����ӣ�������ܻ����������������������磬�ͽ������Ϊ�����ʽ���ܹ���ʾ��������;��������磬�ø�������0��
������β����ˣ�������������β��������1��ˣ����2��18λ����1.f1��1.f2�������˷������ݳ˷���������λ�������롣���ڳ˷�������ֻ��һ�����ƾͿ��Թ��,���������λΪ1,�����������,���Ϊ0,����ֻ���1����;
���������β������ɸ����ʽ�������β�����������ȷ������ķ�������룬�����յij˻��ķ���λ��ָ��λ��β��λ��ʾ��24λ����������ʽ�����
3.2�洢��Ԫ
����FFT�㷨��ԭλ������ص㣬ϵͳ�����������ݴ洢������������RAM��ַͬ����RAM���������RAM������洢������Ƭ�������ݣ��м���������ַͬ����RAM�У��������RAMʼ�մ�ȡ���һ���Ĵ��������ϵͳ�ڴ�����ǰһ�����ݵ�ͬʱƬ�������ݿ������뵽��������RAM�У���֤�����ݼ�ʱ�������㵥Ԫ��û����Ϊ�ȴ����ݶ��˷Ѽ������ڣ���֤��������ȫ�����У���߸ô������Ĵ���������
3.3��ַ������Ԫ
��ַ�������ڿ���������������ȷ�ز������ݶ�д��ַ����ת���ӵ�ַ��FFT�任����������������������㷨,ԭʼ���ݰ�������洢��������RAM��,FFT��������н��м�����ԭλд��ַͬ����RAM�������һ�����ʱ,��ַ��Ԫ�����ĵ�ַ����λ����ģ��õ������ַ�����ݰ�����洢���������RAM�С�
4 ���ܷ���
FPGAѡ��Xilinx��˾��XC2V1000��FPGA��Դ�ܹ����㴦����Ӳ��ʵ�ֶ���Դռ�õ�Ҫ������������Ӳ��ʵ��ռ��FPGA��Դ������£�
Number of Slices 2406 outof 5,120 47%
Number of BlockRAMs 18 outof 40 45%
Number of MULT18X18s 4 outof 40 10%
Ŀǰ�ô�������Ͷ��ʵ�ã����н����ȷ�������ȶ���������ϵͳʱ�ӿɴ�80MHz���ϣ�������������1��ʾ��

��1 FFT��������������
�ô����������Զ��Ƶĸ���FFT����,���ȸߣ��������С�ڣ�80dB,�ܹ�������������״�Ⱦ������Ӧ�ö����ܵ�Ҫ������FFTϵͳ�Ĺ���С��1W��ԶС��DSPϵͳʵ�ֵ�FFTϵͳ��
5 ����
���ĸ�����һ���������1024���Զ���24λ����FFT�����������,����Xilinx��˾XC2V1000��FPGA��ʵ�֣��ﵽ�˸��ٸ߾��ȵ�Ҫ���Զ��Ƹ������ݸ�ʽ�����룬����ȵؼ����˸����������ռ��FPGA��������Դ��Ŀ�������FPGA�߾��ȡ�����Դ���ĵ��ص㡣���Ҹ��������Ժã��ܷdz��������չ�ɿ����õ����ĸ���FFT�ˣ����Թ㷺Ӧ���ڶԾ���Ҫ��ϸߵ������źŴ�������

���㴦���� |