像MIPS技术公司最新的MIPS3234K内核这样的多线程架构正吸引着越来越多的关注,这是因为这种架构无需增加太多的芯片资源或功耗即可获得可观的性能增益。这种硬件多线程的关键优势是,它能使用处理器在等待缓冲回填的空闲周期处理其它线程的指令。
使消费类设备应用程序适应多线程环境的代价一般很小,因为大多数程序已经设计为成组的半独立线程。应用程序线程可以分配给处理器中用于处理单线程的专用硬件资源。多个线程可以被同时分配给这样的硬件,并通过共享CPU周期获得最大的效率。
嵌入式运算面临性能障碍
消费类设备和其它嵌入式计算产品的制造商正在增加Wi-Fi、VoIP、蓝牙、视频等各种新的功能,以往功能的增加都要靠大幅提升处理器的时钟速度来实现。台式机的时钟速度目前已经增加到3GHz以上,即使嵌入式设备也接近GHz级。
但在嵌入式应用领域,这种方法很快就失去了可行性,因为大多数设备的运行收到功耗和资源的约束,这些都限制了处理器速度的进一步提高。时钟周期速度的提高将显著地增大功耗,因此对越来越多的嵌入式设备来说高周期速度将不大可行。另外,处理器速度的进一步提高并不能带来相应的性能改善,因为存储器性能的提高跟不上处理器速度提高的步伐,如上图1所示。
处理器速度已经比存储器快很多,在许多应用场合处理器有一半以上的时间在等待缓存行(cacheline)回填数据。每当缓存丢失(cachemiss)或需要片外存储器访问时,处理器就需要从存储器加载缓存行,将这些字写进缓存,再将旧的缓存行写进存储器,最后恢复线程。
MIPS公司指出,每千条指令接受25次缓存丢失(对多媒体代码来说是一个合理的值)的高端可综合内核如果必须等待50个缓存填充周期,那么将有50%以上的时间处于停止状态。由于处理器速度仍在不断提高,而且比存储器速度的提高幅度大得多,这类问题将变得越来越突出。
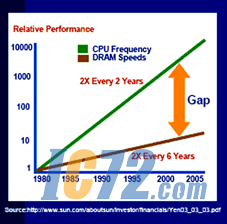
图1:处理器速度超过存储器。
多线程技术
多线程技术解决了这一难题,它可以利用处理器原本用于等待存储器访问的空闲时间处理多个并行程序执行线程。当一个线程停下来等待存储器响应时,另外一个线程会马上提交给处理器,从而保持运算资源的充分利用。
值得注意的是,传统处理器不能采用这种方法,因为它需要大量指令周期才能完成线程之间的切换。要想使这种方法顺利工作,多个应用程序线程必须立即有效,并能逐周期运行。
34K处理器是来自面向消费类设备市场的嵌入式处理器主要提供商的首个多线程产品。每个软件线程在线程环境(ThreadContext,TC)上执行,一个TC包括一整套通用寄存器和一个程序计数器(programcounter)。
每个TC都有自己的指令预取队列,所有队列都完全独立。这意味着内核能在线程间逐周期地进行切换,因此可以避免软件中产生开销。增加更多的TC只需增加很少的额外硅片。TC共享大部分CPU硬件,包括执行单元、ALU和缓存。而且,增加一个TC并不要求CPU拥有另外一个OS软件运行CPU所需的CP0寄存器拷贝。
一组共享CP0寄存器以及与之相关的TC即组成一个虚拟处理单元(VPE)。一个TC运行一个线程,一个VPE管理一个操作系统:如果有两个VPE,那么就可以有两个独立的操作系统,或一个SMP风格的操作系统。带一个TC的VPE看起来就像是传统的MIPS32架构CPU,并且完全兼容MIPS架构规范-其实就是一个完整的虚拟处理器。
34K内核最多可以有9个TC和2个VPE。TC到VPE的联系取决于运行时间。默认情况下所有准备执行的TC都平等分享处理时间,但34K内核也能在某个特殊要求线程可能会“挨饿”的情况下让某个程序影响线程调度,也就是说软件可以控制每个线程的服务质量(QoS)。应用软件与硬件策略管理器(PolicyManager)互动,策略管理器向各个TC分配动态改变的优先级。然后由硬件分发调度器将线程逐个周期地分配给执行单元,从而满足QoS要求。
在像34K这样的多线程环境中,性能可以大大地提高,因为只要一个线程处于等待存储器访问状态,另外一个线程就会占用空闲下来的处理器周期。上图2表明了多线程是如何加快程序执行速度的。当只有线程0运行时,13个处理器周期中只有5个用于指令执行,剩下7个全部在等待缓存行的回填。在这种使用传统处理方式的情况下效率只有38%。

图2:多线程提高了管线效率。
增加线程1就可能使用上述5个用于等待的处理器周期。现在13个处理器周期中用到了10个,效率提高到77%,与最基本情况相比速度加快了一倍。增加线程2后可以完全加载处理器资源,13个执行指令周期可以全部用上,效率达到100%。相比基本情况速度提高263%。
采用EEMBC性能基准的测试表明,34K内核与24KE系列产品相比,只用两个线程就可以提速60%,而硅片尺寸只增加14%,如图3所示。

图3:EEMBC基准性能例子表明只用两个线程性能就有60%的提高。
使软件适应多线程
多线程方法的关键优势是在大多数情况下现有软件只需做极少量的修改就能顺利运行。大多数消费类设备程序已经写成一系列的半独立线程。每个线程可以被自动或人工地分配给专门的硬件TC。
如果当前正在执行的线程由于缓存丢失或其它原因引起的时延而无法继续运行,CPU执行机制就会从那个TC切换到另外一个TC,该TC的线程可以在不浪费CPU周期的情况下运行。程序中线程越多,利用等待存储器访问周期的可能性就越高。
多线程处理对使用或考虑使用RTOS的任何人来说都是非常理想的,因为RTOS程序本身就具有多线程特性。无需为多线程重新编写RTOS程序,因为RTOS可以在程序控制下自动将程序线程映射为TC,其映射方式与将线程映射为传统处理器的方式相同。
如果线程数比TC多,通常需要用到传统的环境切换(contextswitch)。这些环境切换与传统处理器中的是一样的。RTOS保存当前任务的状态,加载另外一个任务的环境并开始执行。多线程环境显然要比传统处理器更适合更多环境的切换,所实现的环境切换速度也更快。
Linux/Windows与RTOS的多线程比较
本节重点介绍相对Linux和嵌入式Windows版本等操作系统而言快速RTOS的优势。Linux的典型实时性能在数百微秒到数毫秒。但在最坏情况下Linux实时性能并不理想。而快速RTOS可以提供确定的实时性能,在单线程处理器上可以达1到2毫秒,在多线程处理器上还会更快。
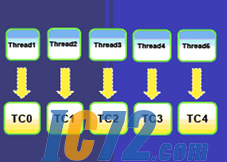
图4:将线程映射为TC
RTOS将唯一资源分配给唯一的TC。传统的做法是将单浮点单元(FPU)分配给TC0。任何执行硬件级浮点运算的线程都需要被映射为TC0,因此所有这类线程必须共享TC0。这就形成了多种有趣的编程选择,特别是用硬件还是软件实现浮点运算的选择。
用硬件实现浮点运算显然速度会更快,但另一方面需要共享FPU。如果线程只做少量的浮点运算,那么用软件实现将更有意义,而需要密集浮点运算的线程通常要用硬件实现,并被映射到TC0。值得注意的是,这个修改不需要记录,因为是否用硬件或软件浮点实现的决定可以由编译器切换实现。
给线程分配权重
如果程序没有给各个线程定义权重,那么程序调度器就会给所有线程分配相同的权重,另外也可以使用时间分段技术使线程依据用户指定的权重共享CPU周期。分配权重相当于将适当比例的CPU周期分配给各个具体线程。线程权重由RTOS透明地映射为硬件TC。
一些现有程序是针对传统处理器设计的,其前提条件是假设在有高优先级的线程准备好时低优先级线程将被禁止运行。在嵌入式编程环境中,准备好的意思是线程运行所必需的全部条件都得到了满足,阻止它运行的唯一因素是它的优先级。
多线程可破坏这种条件,因为无论高优先级线程是否停止,低优先级线程都能运行。编写取消这种状态的代码可优化性能。
另外一方面,根据这种条件编写的现有代码无需修改就能运行在多线程处理器上,只需简单地设置操作系统开关,使其只允许相同优先级的线程同时被加载到TC。在设置这个开关时,需要确保给那些能够并行运行的线程尽量分配相同的优先级。
可中断的重要性
在传统的嵌入式应用中中断是非常重要的,因为它们提供了主要的、在许多情况下也是唯一的线程间切换方式。中断在多线程应用中也起着相同的作用,但有一个重要的区别,即在多线程应用中,线程间的切换不仅要通过中断,还要使用空闲CPU周期。
需要尽量避免在修改关键数据结构时中断某个线程,同时起用另外一个线程对同一结构作其它修改。这将导致数据结构处于不一致的状态,极易引起灾难性后果。
大多数传统应用解决这个问题的方法是,当ISR或系统服务正在修改RTOS中关键的数据结构时暂时锁住中断。这种方法可靠地阻止了任何其它程序跳进来对执行代码正在使用的关键区域做出不恰当的修改。
然而在多线程环境中这种方法是不够的,因为有可能被切换到不受中断锁定控制的不同TC,从而可能对关键区域做出修改。该问题可以利用34K架构中的DMT指令解决,当数据结构在修改状态时可禁止多线程功能。
除了这些相对简单的例外情况外,设备代码在从传统设备移植到多线程设备时无需修改就能直接运行。因此,我们能够利用以往被传统RISC处理器浪费的CPU周期,充分发挥多线程性能优势。多线程可以满足当前和未来需要高性能的消费类、网络、存储和工业设备应用要求,而成本和功耗只有少许的增加。
与主要的竞争技术--多内核技术相比,多线程有更小的硅片面积和更低功耗的优势,而且编程简单,现有程序只需做少量修改甚至不用修改就能运行。多内核方法也有它自己的优势和强项,因此没有理由证明这两种方法不能融合出一种最佳方法。在要求高性能、低成本和最小功耗的应用场合,多线程是一种极具竞争力的方案。 |