��������ij��Ӧ�õ����ݷ��ʷ�ʽ�����Գ�����ô�����DZ�ڼܹ��еĴ洢����ϵͳ��Դ���Ӷ���������չ�IJ���Ӧ�á�
���ڵ��˽ṹ��Ƕ��ʽ������Խ��Խ������������������Ƕ��ʽ��ý�崦��Ӧ�÷����Ҫ���Ƕ��ʽ�ṹ�ѳ�Ϊ�����һ�������Ч;����ͬʱҲΪ��ο���������ö�˽ṹ��Ӧ������������ս��Ŀǰ����Ҫ�����뼼���Ϳ������߸���Ľ������������ʹ��˽ṹ��Ӧ�û�óɹ����������������������ͨ���ֹ�ת����ʽ��˳�����ת��Ϊ���г�����ʵ�ֵġ�����ȱ�����ж����ʶ�Ŀ������ߣ�ʹ���������Խ���������������ˣ����û��Ԥ����Ч�ɿ��Ĺ��̹滮�������ò����Ӧ��������Ч�ʵ��£��Լ��ӳٲ�Ʒ����ʱ������⡣
�������Ϊ���Ӧ�������Ŀ����ṩ��һ���ܺõ���㣬���������̿���ʱ�䡣���Ľ���ϸ˵��Ƕ��ʽ��ý��Ӧ����������ƿ�ܣ�ͬʱ�����ĵ�������ģ��Ҳ����չ����������Ӧ���С��ÿ���ۺ��˶�ý��Ӧ���������е����ݲ��нṹ����˵�������ͨ����Чʹ��DZ�ڼܹ�����Ч������������
����Ʋ��������Ĺ�������������ս��һ�ǿ���һ����Ч�IJ����㷨��������Ч���ô洢������DMA��ֱ�Ӵ洢���ʣ�ͨ���ͻ�������ȹ�����Դ����������У�˳�����е�Ӧ�ó�������ܿɸ��ݿ��ô������˵���Ŀ������չ��
ͨ��ʵ��Ӧ�ó���IJ��д����ж��ַ�������ЩӦ�ó������Ϊ���еIJ��У����е�������൱�����Ҳ���������ݴ�ȡģʽ�����ܵ���������ѧӦ�ó���Ͷ�ý��Ӧ�ó���IJ���ͨ������ʵ�֣���Ϊ���ǵ����ݴ�ȡģʽ����Щ������Ӧ�ó����������Ԥ�⡣�����ص�������Զ�ý���㷨�IJ��м����������㷨��Ҫ�ܸߵĴ����������ҳ�����Ƕ��ʽϵͳӦ���С�
��ý��Ӧ�ó����д������ݵIJ��м���һ������֡������֡�е�һ�����֮��IJ��������кܴ���ͨ������������ԽС���ڹ�����Ԫ�������紦�����˺�DMAͨ������֮�������ͬ������Խ�ߡ�����ԽС�����г̶�Ҳ��Խ�ߣ�������ͨ����ҲԽС���෴�����������Ҫ��ϵ͵�ͬ���ԣ���Ҳʹ����ͨ����������ˣ�����Ӧ�õIJ�ͬ���ͺ�ϵͳ�����������Ҳ�����˲�ͬ�IJ��м���
��Ҫ˵�����ǣ��Կ���չ���������Ŀ����������ڶԻ������硢�ּ��洢����ϵ���Լ�����/DMA��Դ����Ч���á�ϵͳ�ϸ�ĵ��ĺ͵ͳɱ��������������ЩҪ�ض��ṹ��Լ������˻����µ����Ҫ��ĸ���Դ����Ч���÷�ʽ�����Ľ����˼�����ADI��˾��BlackfinADSP-BF561˫�˴������϶���Դ������Ч�����ķ�����
��ý������������
Ϊ��ʵ�����ݲ��У���Ҫ�����������ҵ�����һ����һ�����ݿ飺�ܹ������������������������Ĵ������������������ݿ���Խ���ͬ�������������㷨��Ҫ�ҵ��������ݿ飬��Ҫ����Ҫ���������ģʽ������һ��Ӧ�õ����ݴ�ȡģʽ��
���ڴ������ý��Ӧ�ã����Խ����ݴ�ȡģʽ������2-D���ռ���3-D��ʱ������ģʽ����2-Dģʽ�У����������ݿ鱻�����ڵ�������֡�ڣ�����3-Dģʽ�У��������ݿ���Կ�Խ��֡���ڿռ����У����Խ�֡������N�������к���Ƶ֡�����ɵ�Ƭ�Σ�����ʱ�����У����Զ���������һ��ϸ�ֵ�֡����ͼƬ�飨GOP������
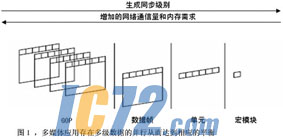
����Ƭ�λ�������ݴ�ȡģʽ���㷨��ͬ����Ҫ��ܸߣ�����Ҫ���ٵ����紫������������Ϊ�ּ��Ĵ洢����ϵֻ��洢ͼ�����ݵ�һ���֡�����֡��ͼƬ�����͵����ݷ���ģʽ���ּ��Ĵ洢����ϵ����Ҫ�洢�������ݣ�����ͬ���Ե�Ҫ������Ե͵öࡣ������Ϊϵͳ�IJ������������˵�Ե�ʡ�ͼ1˵���˶�ý��Ӧ�������еIJ��м���ͬʱ���ĸ���������ص�ͬ���Ժ�����ͨ�������˶Աȡ�
ͼ2˵����ADSP-BF561�Ľṹ���ýṹ������а���������ָ������ݴ洢�����ֱ�����������������ר�С��ýṹ������������L2�洢�����ⲿ�洢�����û����ÿ����õ��ٲ÷��������е���Χ�豸��DMA��Դ���ӵ���һ���������ϡ�ADSP-BF561������DMA��������ÿ����������MDMA���洢��-DMA��ͨ·��ɡ�L2�洢����ÿ����������֮�䶼ͨ���������������ӣ����ⲿ�洢����������������֮������һ�������������ӡ�
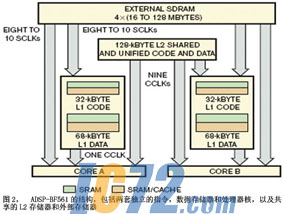
���мܹ�������DMA��ʽ������������ּ��Ĵ洢����ϵ����Ϊ����һ��ѡ��ĸ��ٻ��沢�������κ����ݡ�ֻҪ�������Ƶ�Ŀ��Ӧ�õ����ݷ���ģʽ�����������DMA��������ݽ�����Ч�Ĺ�������ʹ�ø��ٻ�����Ҫ���ܲ�ȷ���ķ���ʱ�䣬���ٻ���ʧ��Ĵ��ۣ��Լ���Ҫ�ϸߵ��ⲿ�洢������������DMA���棬�����ڴ���������Ҫ����֮ǰ�ͽ���������L1�洢����ϵͳ�ں�ִ̨�д����������������Ϊû�в�������ʹ����������ͣ������
����ÿ��DMA�������϶�������MDMAͨ·��ϵͳ���ʱ�����Խ�MDMAͨ·�ڴ���������ƽ�����䣬�Ӷ����ԶԳƵؽ��в��в�����
���ھ��н�С�������ݷ���ģʽ��Ӧ�ã��������ɵ����ö�L1��L2�洢���Ŀ��ٷ��ʣ�Ҳ����ֱ�ӽ����������ݿ����Χ�豸���͵�L1��L2�洢����������Ҫͨ�����ٵ��ⲿ�洢�����ʣ������ɽ�ʡ�������洢��������MDMA��Դ���������������ݴ���ʱ�䡣
����ijЩ���ýϸ߲㼶���ȵ����ݷ���ģʽ��Ӧ�ã��洢���Ϳ��ܳ�Ϊ����ƿ������Ϊ��С��L1��L2�洢���㼶�������ɴ���������֡��Ȼ������������֮֡����Ȼ��������ݹ����ԣ������ֹ���ͨ��Ҳ�������ڿ�����֡�Ľ�С���ݿ顣����ܽ����й���������֡�����һ���ϴ�Ĵ洢�ռ䣨��洢�����У��Ϳ��Խ�ÿһ֡�еĶ������ݿ����������еĴ������˽��д����������Щ���������ݿ������֡С�ö࣬�����ڷ���L1��L2�洢�����������Ϳɼ��ٴ洢����ȡ�ӳٴӶ���Ч�ش������ݡ�
��ȻL2����洢�����ж������������ӣ��������������Թ�����Щ�洢���ӿ����ߡ���ˣ�Ӧ��������������������������ͬʱ��ͬһ����Ĵ洢�����д�ȡ�����������������·���������ӳ١�Ϊ�˼�����·����״̬������ܹ�Ӧ����Ŀ������������ݵ�ӳ�䣬Ҫ��һ������������Ҫ����L2�洢���ˣ�����һ������������Ҫ�����ⲿ�洢��������������£���Ȼ����������ɶ����ⲿ�洢�����ʻ���ֽϴ�ķ����ӳ٣����ܵķ����ӳ���ȻҪ�ȴ�����·����״̬�µ����С��
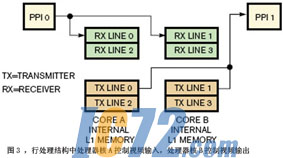
�ýṹ�ܽ����е���������ӿ�������һ�����������ϣ����е��������ӿڷ��䵽��һ���������ϡ�BF561��ϵ�ṹ��������PPI����������ӿڣ���ͨ��PPI��Ƶ����/����ӿڣ�����ʵ������������Ƶ֡�Ķ���������
����жϴ���ʱ����������Ĵ���ʱ��Ҫ�̣����ɽ����е�����ӿڷ��䵽һ�������������Ա��ڱ�̣��϶̵��жϴ���ʱ�䲻��Ӱ�������������˵ĸ���ƽ�⡣
������������ģ��
�������ݷ���ģʽ�����ȣ������Զ�������������ܣ��д�����������鴦��������֡������ʱ���Լ�GOP������ʱ�����ij��Ӧ�ó�������ݷ���ģʽ����������ģ���е��κ�һ�֣��Ϳ��Բ�����Ӧ�������ṹ�������ͬһ�����������ֻ���ִ����㷨�������Խ��⼸�������ṹ���������ʵ�ַǶԳƵIJ��д�����
���д���ģʽ�У�ֻ���м�������ԡ���Ҳ����˵��ֻ��������������֮���������ԡ�ÿ�������γ�һ�����ݿ飬���������������˶�����������ͼ3˵�����д��������ܹ���������ģ�͡�ͼ�У���������A������Ƶ���룬��������B������Ƶ�������������A��B֮��������ж�����MDMAͨ�����й�����L1�洢��ʹ�ö�������������Ա��������������DMA���ݷ���֮����ֵ���·����״̬��������������֮��ÿ�����ݵ�ͬ������ͨ��һ�������ź���ʵ�֡����д���ģʽ�У����õ��������˷�ʽ������ֱ�Ӵ���L1�洢��Ҳ�������ƣ����Խ�ʡ�ⲿ�洢��������DMA��Դ���д��������ܹ���Ӧ��ʵ������ɫ�ʱ任��ֱ��ͼ���⻯���˲����Լ�������
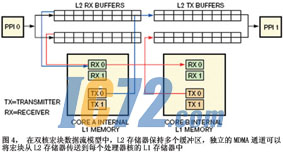
ͼ4˵���˺�����ݷ���ģʽ��������ģ�ͣ����Խ�����ĺ����������������֮�䴫�͡�L2�洢�����ֶ�����ݻ�����������L2�洢�����䵽ÿ���������˵�L1�洢�����ж�����MDMAͨ����L1�洢��Ҳ���ֶ�����ݻ��������Ա�����DMA�ʹ����������ݷ��ʹ����в�����·���á����д����ṹ���ƣ��ýṹ�д�������A�Կ���������Ƶ�ӿڣ���������B��������ӿڣ������ź���ʵ��������������֮���ͬ�������������ܹ���Ӧ��ʵ��������Ե��⣬JPEG/MPEG�ı�/�����㷨���Լ��������롣
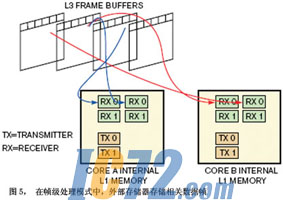
��֡������ģʽ�У��ⲿ�洢���洢��ص�����֡����������֡�������У�֮������Ե����ȣ�ϵͳ������֡���ӿ鴫�͵�L1��L2�洢����ͼ5˵����֡�����������ܹ�������ģ�͡�����������£��ٶ�ij������ڲ�ͬ֡���������ԣ�ϵͳ������֡�ĺ�鴫����L1�洢���������������ܹ����ƣ���������A�Կ���������Ƶ�ӿڣ���������B���������ӿڣ������ź���ʵ��������������֮���ͬ�����������ܹ���Ӧ�����˶�����㷨��
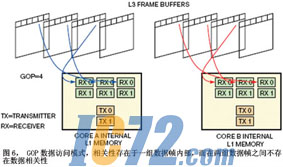
��GOP�������ܹ��У�ÿ���������˶��������˳�������֡��֡�������ṹ��GOP�����ṹ֮�����������֡�������ṹ����֡����ɿ��֣���GOP���ṹ��ͨ��ʱ��֡���У�����ʵ�ֲ��д���������GOP���ݷ���ģʽ������Դ�����һ������֡�ڲ�������������֮֡�䲻������������ԣ���˴������˿���������ض�ÿ������֡���д�����ͼ6˵���˸ýṹ��������ģ�ͣ���֡�������ṹ���ƣ�ϵͳ�ɽ���֡���ݿ鴫�����������˵�L1��������Ϊ����Ч�����ⲿ�洢���Ľ���洢��ṹ��ϵͳ�ڴ������˼����Ļ��ִ洢����ADSP-BF561��ÿһ���ⲿ�洢����֧�ֶ����ĸ����ڲ�SDRAM�洢���顣��һ�ṹ��Ӧ��ʵ���б�/�����㷨����MPEG-2/4��
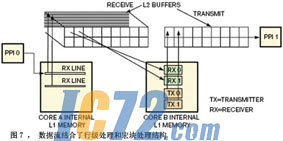
��ʵ�ʵ�Ӧ���У�ϵͳ�������ö����㷨����������������ÿ���㷨�������õ���ͬ�����ݷ���ģʽ����������£�����Խ��⼸�������ṹ����������һ�������Ӧ�á�Ϊ���ö�˽ṹ���ɲ�����ˮ������ʵ���㷨�IJ��в����������ֲ��в����Dz��ԳƵģ���Ϊ��ͬ���������Ͽ���ִ�еļ����Dz�ͬ�ġ�Ȼ����ϵͳ���Է���һЩ���������������˵Ŀ���ָ���ϣ��ڱ�������Ե�ͬʱҲ�ﵽ�˴������˵Ĺ�����ƽ�⡣ͼ7˵�����м������ͺ�鴦�����ϵĴ����ṹ�е�������ģ�͡�
��ijЩ����Ӧ���У�������ݿ�֮��Ҳ�������������ԣ����ݷ���ģʽ��Ȼ�ǿ�Ԥ��ģ�������չ����һ������һ���е�����֮�⡣���磬�˶�������Ѱ�Ϳ���ʹ�ü������ڵĺ�顣��Ȼ���ݷ���ģʽ��Ȼ�ǿ�Ԥ��ģ���ϵͳ���㷨����������Ҫ���ʶ�����ݿ顣����������£������Զ�������ܽ�����������ʵ����Ч�IJ��в��������磬������м��������ԣ�����ͨ�������д����ṹ��N�������е�֡��Ԫ���͵�ÿ���������˵�L1�洢���С��������Ƶķ����������ԶԺ�鴦���ṹ������չ����L2�洢���н���ֹһ����������ڲ�L1�洢����
������ܷ���
Ϊ�˶�˫�˴�����������ܽ���������AD��˾����������ģ�����ȿ�����һ���Ӧ������������˫��ʵ�ֽ����˶Աȡ��ο����ס�1�������˵���ģ�͵ĸ���ϸ�ڡ�Blackfin���е�ϵͳ�Ż�������ȫ������Ч��ʹ�ÿ��ô�����Ϊ�˷�������˾ֻ�Ի��������ܹ��Ĵ����ٶ����˶Աȣ���û�п��Ǽ�����ϵ������ܹ���
��ν������ָΪ������NTSC�����ҵ���ϵͳίԱ�ᣩ��Ƶ�����ʵʱ��Ҫ�����ڴ����������Ĵ������˼������ڡ�����һ����600MHz���еĴ������ˣ�Ϊ������ʵʱԼ������������ÿһ���ؿ��õ�������Ϊ44������/���ء��κδ������˷��������ݶ�ֻ��һ�����ں����ڣ���Ϊ���е����ݷ��ʶ��Ƕ�L1�洢���ķ��ʡ���������û�а����ж�������ӳ١�
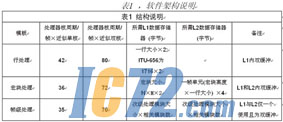
���1��ʾ��˫�˴����ṹ�����������ṹ�Ĵ����ٶȶ���Ч��������������л�˵����L1�洢������ÿ���������˵Ŀ����������Լ�ÿ�������ܹ�����Ĺ����洢�ռ䡣��Щ�����ܹ�Ӧ��ADi��˾��DD/SSL���豸��������/ϵͳ����⣩ʵ�ֶ���������ݵĹ����� |