上回书说到P+Q的RAID6在Intel芯片里的实现。
其实P+Q只是一种算法,Intel IOP里面的硬件加速引擎并不是必须的。有一些产品就采用了PowerPC等不含P+Q引擎的CPU,一样不耽误P+Q RAID6功能。GF转换表在软件里完成就是了。
四、准RAID6技术
除了P+Q RAID6,还要好多种办法可以实现对两颗磁盘掉线的容错。
网友Billylee提供的Intel讲义中就提到一种Dual-XOR算法,这种方法就是取横向和斜向两个方向进行XOR运算,这样每个应用数据都在两个校验中留下痕迹,当两颗磁盘掉线时,就可以恢复数据。
但是Dual-XOR的恢复工作异常复杂艰苦,并不实用。很多技术人员研究这种算法的意义,完全是把它当作未经优化的原型思想。
如图,Pa是横向的校验,跟RAID5完全一样:
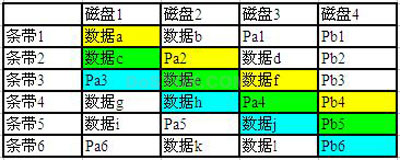
Pa1 = 数据a XOR 数据b
Pa2 = 数据c XOR 数据d
…………
Pa6 = 数据k XOR 数据l
Pb是斜向校验,定义为:
Pb4 = 数据a XOR Pa2 XOR数据f
Pb5 = 数据c XOR 数据e XOR Pa4
Pb6 = Pa3 XOR数据h XOR 数据j
可以看出Dual-XOR的校验生成过程比P+Q要简单,但是根据“麻烦守恒定律”,正向工作简单的事情,一般反向工作都会复杂。
备份和恢复一般也遵循这个规律。(别跟我提CDP,那东西遵循的是广义麻烦守恒定律。每个I/O都打个时间标签,还都当宝贝存着不扔,这能是个不麻烦的事吗?Sorry,又扯远了。)
当两颗磁盘掉线的时候,Dual-XOR的算法只能支持逐个数据块的恢复,而且不同条带之间还要共同参与计算。
比如图中的磁盘1和2掉线,恢复数据e的时候,就要至少动用到数据f、Pb3、Pa4和Pb5。而数据c和Pa3的恢复还要依赖数据e的恢复。
总之恢复起来是件贼头痛的事情!
虽然Intel的Dual-XOR理论意义大于实际意义,但其改良的版本RAID-DP却已经被NetApp产品化。NetApp之所以喜欢这个类似Dual-XOR的RAID-DP算法,原因也很简单。
NetApp原本用的就是RAID4,而不是RAID5,其算法的中心思想就是每次I/O只跟两颗磁盘打交道就OK,自然就不会在乎RAID-DP中很多动作都只跟两、三颗磁盘打交道。(这个思想也许在很多RAID5的Fans看来有点奇怪,难道不是磁头越多性能就越好吗?但是人家NetApp这么多年的经验都集中在WAFL文件系统上,而WAFL文件系统又是专门针对这种思想优化的。所以NetApp对这个略有异类的思想不仅没有放弃,而且越研究越起劲。
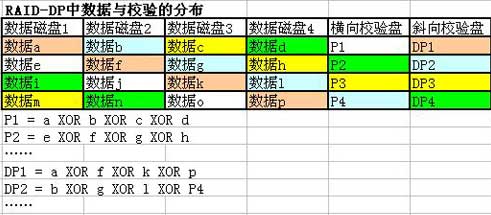
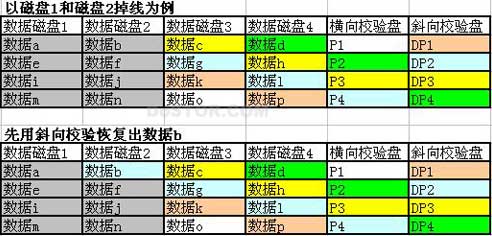
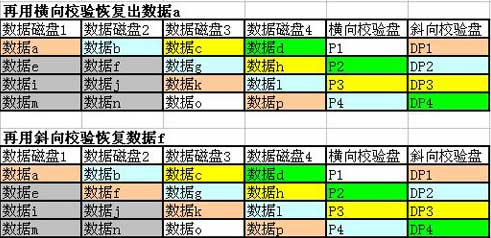
这个递归式数据恢复机制简直像在玩RPG游戏,但是对WAFL文件系统来说,却的确是最合适的选择之一。
除了RAID-DP,还有X-Code编码、ZZS编码、Park编码……都可以看做是“准RAID6”。
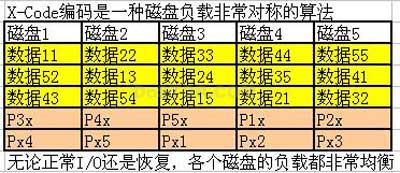
待续
|