随着人们对现代通信系统要求的不断提高,对处理器的性能要求也在不断增加。以往满足不断增长的系统性能要求的方法是提高时钟速度。然而,高速设计的压力和热问题复杂性的增加意味着这种方法已经接近微处理供应商的能力极限。即使近年来工艺技术有了大幅提高,硅片面积因此也有了显著缩小,运行速度明显加快,但也无法跟上性能要求提高的步伐。
一种趋势是增加额外的处理器。然而,使用额外的处理器会造成架构复杂性增加、系统功耗上升,更不用说价格更高的PCB。越来越多的芯片供应商开始采用在单块硅片上集成多个处理内核的设计方法。
发展趋势
向高级电信计算架构(ATCA)和微电信计算架构(uTCA)等业界标准发展的趋势允许复用机箱、机架和风扇组件,从而不仅可以降低总的系统成本(因为允许使用常用组件),而且能够通过减轻设计师的设计负担来缩短产品的上市时间,设计公司也因而能集中精力于更高层的任务,例如系统架构的开发。
这一趋势的形成原因部分是由于串行/解串器(SERDES)技术即高速串行接口的出现。SERDES不仅极大地提高了承载卡和背板的数据传输速度,而且通过取代并行总线架构而简化了设计工作,避免了并行总线布线、数据扭曲(data skew)、时钟负载等问题。
工业标准架构允许原始设备制造商(OEM)快速转向更加模块化的设计。AdvancedMC(AMC)的“即插即用”特性能让处理单元迅速得到替换和/或升级(至少就硬件来看是这样)。
当然,AMC规范的这种模块化特性也是有代价的,AMC规范在电路板面积、元件高度和模块电源方面作的限制给电路板设计师提出了新的挑战。硅片制造商通过努力使这些硅片是AMC“友好的”来应对这些挑战,如使处理器的功耗更低、封装体积更小,并集成进更多的功能,不再需要外围桥接芯片。
存储器交错处理技术
对于大多数高性能系统来说,高性能存储器接口对保证高吞吐量甚为关键。通常,在较差的系统设计中,具有极高性能的处理器常常处于一种无数据处理的“饥饿”状态。
提高总吞吐量的一种方法是采用存储器交错处理(memory interleaving)。存储器交错处理能使处理器在指定时间内读写更多的信息,从而有助于减少潜在的瓶颈问题。
交错处理的原理是将系统存储器划分成多个块。通常存储器被划分成2个或4个块。这些系统也被称为双路或四路交错系统。即使有两个物理上独立的存储器库,软件也视之为一个存储器块。
为了实现存储器交错处理,必须能够使用一组单独的控制线访问每个存储器块。一旦开始对第一个存储器块的访问,对第二个块的访问也能同时进行。
在交错处理的存储器系统中,仍有两个DRAM物理库。然而,处理器在逻辑上只看到一个存储器库。对存储器的访问是轮流进行的,先是库1的数据,然后是库2的数据,然后又再是库1的数据。逻辑库的所有偶数长字存放在物理库1中,所有奇数长字存放在物理库2中(见图1)。这样做具有明显的速度优势,因为对这些存储器的存取采用的是独立的总线,时间上可以同时进行。
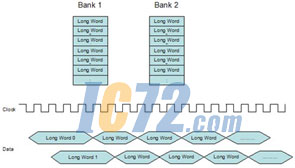
图1:存储器交错处理时序。
千万不要把存储器交错与传统系统中使用多个存储器库相混淆。这些“传统”系统只是简单地通过增加存储器库来提高存储器容量,通常插入双列直插存储器模块(DIMM)。虽然新增的库可能被赋予独立的片选线,但它们一般都共享控制线,比如行地址选通(RAS)和列地址选通(CAS),因此不允许同时访问。两个存储器控制器之间的交错能力可以为系统设计师提供两大好处:首先,它不需要处理器利用软件去平衡对两个存储库的访问,而是可以自动平衡,因此能让处理器充分发挥存储器控制器的带宽优势;其次,它允许一次打开两倍具有空间方位性的DRAM页,这样可以显著提高打开页被访问到的概率,从而减小延迟。
存储器交错处理过去一直没有用于嵌入式系统,因为新增存储器和支持这种架构所需的复杂芯片组成本都非常高。然而,随着存储器成本的不断下降,PC机市场的大力推动以及大量处理器中集成具有交错处理能力的存储器控制器,这种技术现在已经走向应用。
例如,MPC8641D Power处理器能通过存储交错技术访问集成在内部的DDRII DRAM控制器。该处理器支持两个DDRII存储器控制器,存储器事务可以根据地址分派给DDRII控制器1或DDRII控制器2。另外,控制器也可以经过配置支持两个存储器控制器之间的交错事务。两个存储器控制器之间的交错处理可以以缓存线(cache line)或页为基础进行。
AMC参考平台
在仔细考虑了对多内核AMC卡的要求后,我们会发现各种要求之间似乎有矛盾或不一致的地方。初看起来确实是这样,例如:高处理器性能但要最小化功耗;双存储器库,要支持交错,但只有有限的电路板面积;不存在系统瓶颈的高速SERDES接口;除了“宽管(Fat Pipe)”外,还要支持“普通选项(common option)”接口。
下面让以飞思卡尔半导体公司推出的MPC8641D AMC参考平台为例(见图2),揭示此类架构如何克服上述“问题”的。
MPC8641D的两个内核都以1,500MHz速率运行时的处理器典型功耗为32W,也即这款处理器仅需32W功耗就能提供3GHz的Power处理能力。因此给整体设计带来了很大的好处:
1. 功耗的减少可以简化电源设计;
2. 由于需要散发的热量少,所以可以用较小的散热器,同时由于减少了对昂贵的专用工具解决方案的需求,设计将更简单、成本也更低;
3. 较小的散热器能使电路板轻易满足对AMC卡的机械要求;
4. 由于是“较冷”的解决方案,整体可靠性提高了。
MPC8641D支持两个独立的64位DDRII控制器。这些存储器控制器是集成在内部的,因此不仅简化了设计,而且不再需要使用外部的桥接芯片,从而节省了宝贵的电路板面积。卡上的DDRII库在物理上是用分立器件实现的。这种实现方法有两大优点:首先,整体解决方案在体积上要小于用DIMM实现的解决方案;其次,由于分立器件不高,因此可以把这些器件放在AMC卡的反面,并保持在高度范围之内。在MPC8641D AMC卡上,两个库都放在正面,并与处理器相邻(如图3所示)。

图2:MPC8641D AMC卡
由于分立DDRII实现的高度低,因此需要时可以安装较大的散热器。例如,当卡需要在较高温度或空气流动不畅的环境下工作时就需要用较大的散热器。因此,这种实现方法具有很大的灵活性。
AMC规范开发背后的源动力是背板通过SERDES接口可以获得较高的数据速率。像串行RapidIO或PCI Express等高速互连总线就是这样的接口。通常这些接口需要用专门的桥接芯片或FPGA实现。这些额外接口芯片可能导致系统中的瓶颈、额外的成本和更大电路板面积等问题。
MPC8641D集成了支持串行RapidIO和PCI Express的两个SERDES接口。这种集成式模块不仅取消了外部芯片,而且避免了潜在的瓶颈问题。由于内部集成了这些接口,可以用内部DMA引擎直接将数据从I/O移动到系统内存。因此不仅去除了瓶颈,而且无需处理器介入就能实现数据传送。
除了“宽管”外,AMC规范要求在边沿连接器上提供“普通选项”区域。该区域一般用作两个千兆位以太网、SERDES接口。就像"宽管"接口一样,处理器芯片中也集成了千兆位以太网接口。同样,这样做能带来更小电路板面积、更简单的设计和消除潜在瓶颈等好处。事实上,MPC8641D支持4个千兆位以太网端口。在AMC卡上,两个千兆位以太网在通用功能区使用,另外两个通过前面板上的RJ45连接器接出来。
当然,硬件只是整个解决方案的一部分。毫无疑问,设计最复杂的部分,事实上也是最难的架构决策需要根据软件结构实现。
在多重处理系统中,软件可归结为两种基本选择,即对称多重处理或非对称多重处理。采用哪种系统很大程度上取决于总体系统要求,基本上是系统想在输入/输出、任务处理、系统延时等方面达到的要求。每种方法都有自己独特的优势。
对称多重处理方法认为只有一个操作系统高效地拥有系统中的所有资源。例如在MPC8641D双核处理器上,操作系统将每个内核看作一个资源。对于非对称多重处理,每个内核运行一个独立的操作系统。资源一般在各个处理单元之间分配。
每种方法都允许用户充分利用设计的双核特性以最大化性能。例如,一个内核处理数据任务,而另外一个内核处理控制任务。或者,第一个内核将各种任务卸载给第二个内核。
MPC8641D内部支持这些架构。例如,针对数据缓存的硬件增强型的、改进的/排它/共享/无效(MESI)的缓存协议可确保缓存一致性。
本文小结
电信产业的发展趋势是采用能够最大化电路板面积和功耗等方面的投资回报的解决方案,因此硅片制造商和电路设计师的压力正在与日俱增,他们不仅需要提高MIPS性能,还要最小化功耗和整机外形。
在硅片供应商努力满足这些要求的同时,他们开发的处理器也越来越复杂,从而给板级设计师带来了更多的潜在性挑战。看起来,设计多内核处理器以满足AMC规范要求对一个公司来说似乎是个艰巨的任务,在外形、热要求和板级功能等方面的严格规范给板极设计师和设备制造商造成了很大的困难。然而,有硅片供应商提供的参考平台和设计保证,这些问题可以迎刃而解。用户为了缩短产品上市时间,纷纷利用硅片制造商提供的参考设计。这些设计可以是实际电路板,也可以是经过验证的详细设计,用户可以在此基础上开展他们自己的工作。 |