ЫцзХаХЯЂЛЏММЪѕЕФЗЂеЙКЭЩюШыЃЌЦѓвЕЖдЪ§ОнЕФвРРЕВЛЖЯдіЧПЁЃгыДЫЭЌЪБЃЌМБЫйдіГЄЕФЪ§ОнСПвВИјЙмРэКЭЪЙгУЖМДјРДСЫШЋаТЕФЬєеНЁЃIDCзюаТБЈИцЯдЪОЃЌ2007ФъаТдіЪ§ОнСПЃЈ281 ExaByteЃЉвбОГЌЙ§ЫљгаПЩгУДцДЂНщжЪзмШнСПЃЈ264 ExaByteЃЉдМ6%ЃЌВЂдЄМЦ2011ФъЪ§ОнзмСПНЋДяЕН2006ФъЕФ10БЖЁЃУцЖдЪ§ОнЕФБЌеЈаддіГЄЃЌНіНіЬсИпЯЕЭГдЫЫуФмСІКЭдіМгДцДЂНщжЪШнСПвбОВЛФмТњзуИпЫйЗЂеЙЕФИїжжЪ§ОнгІгУЃЌЖдИпаЇЪ§ОнЫѕМѕММЪѕЕФашЧѓвбОж№ВНЯдЯжГіРДЃЌВЂЧвдНРДдНЦШЧаЁЃ
ФПЧАФмЙЛЪЕЯжЪ§ОнЫѕМѕЕФММЪѕжївЊгаСНжжЃКЪ§ОнбЙЫѕЃЈData CompressionЃЉКЭжиИДЪ§ОнЩОГ§ЃЈData De-duplicationЃЉЁЃМђЕЅРДЫЕЃЌЪ§ОнбЙЫѕММЪѕЭЈЙ§ЖдЪ§ОнжиаТБрТыРДНЕЕЭЦфШпгрЖШЃЈredundancyЃЉЃЛЖјжиИДЪ§ОнЩОГ§ММЪѕдђзХблгкЩОГ§жиИДГіЯжЕФЪ§ОнПщЁЃ
Ъ§ОнбЙЫѕ
Ъ§ОнбЙЫѕЕФЦ№дДПЩвдзЗЫнЕНаХЯЂТлжЎИИЯуХЉЃЈShannonЃЉдк1947ФъЬсГіЕФЯуХЉБрТыЁЃ1952ФъЛєЗђТќ(Huffman)ЬсГіСЫЕквЛжжЪЕгУадЕФБрТыЫуЗЈЪЕЯжСЫЪ§ОнбЙЫѕЃЌИУЫуЗЈжСНёШддкЙуЗКЪЙгУЁЃ1977ФъвдЩЋСаЪ§бЇМвJacob Ziv КЭAbraham LempelЬсГіСЫвЛжжШЋаТЕФЪ§ОнбЙЫѕБрТыЗНЪНЃЌLempel-ZivЯЕСаЫуЗЈЃЈLZ77КЭLZ78ЃЌвдМАШєИЩБфжжЃЉЦОНшЦфМђЕЅИпаЇЕШгХдНЬиадЃЌзюжеГЩЮЊФПЧАжївЊЪ§ОнбЙЫѕЫуЗЈЕФЛљДЁЁЃ
Lempel-ZivЯЕСаЫуЗЈЕФЛљБОЫМТЗЪЧгУЮЛжУаХЯЂЬцДњдЪМЪ§ОнДгЖјЪЕЯжбЙЫѕЃЌНтбЙЫѕЪБдђИљОнЮЛжУаХЯЂЪЕЯжЪ§ОнЕФЛЙдЃЌвђДЫгжБЛГЦзїЁАзжЕфЪНЁББрТыЁЃФПЧАДцДЂгІгУжабЙЫѕЫуЗЈЕФЙЄвЕБъзМЃЈANSIЁЂQICЁЂIETFЁЂFRFЁЂTIA/EIAЃЉЪЧLZSЃЈLempel-Ziv-StacЃЉЃЌгЩStacЙЋЫОЬсГіВЂЛёЕУзЈРћЃЌЕБЧАИУзЈРћШЈЕФЫљгаепЪЧHifn, Inc.
LZSЫуЗЈЛљгкLZ77ЃЈШчЭМвЛЃЉЪЕЯжЃЌжївЊгЩСНВПЗжЙЙГЩЃЌЛЌДАЃЈSliding WindowЃЉКЭздЪЪгІБрТыЃЈAdaptive CodingЃЉЁЃбЙЫѕДІРэЪБЃЌдкЛЌДАжаВщевгыД§ДІРэЪ§ОнЯрЭЌЕФПщЃЌВЂгУИУПщдкЛЌДАжаЕФЦЋвЦжЕМАПщГЄЖШЬцДњД§ДІРэЪ§ОнЃЌДгЖјЪЕЯжбЙЫѕБрТыЁЃШчЙћЛЌДАжаУЛгагыД§ДІРэЪ§ОнПщЯрЭЌЕФзжЖЮЃЌЛђЦЋвЦжЕМАГЄЖШЪ§ОнГЌЙ§БЛЬцДњЪ§ОнПщЕФГЄЖШЃЌдђВЛНјааЬцДњДІРэЁЃLZSЫуЗЈЕФЪЕЯжЗЧГЃМђНрЃЌДІРэБШНЯМђЕЅЃЌФмЙЛЪЪгІИїжжИпЫйгІгУЁЃ
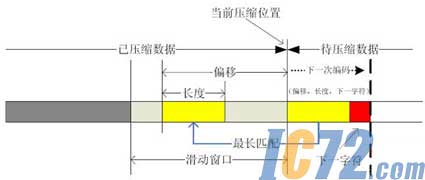
ЭМвЛ LZ77ЫуЗЈЪОвтЭМ
Ъ§ОнбЙЫѕЕФгІгУПЩвдЯджјНЕЕЭД§ДІРэКЭДцДЂЕФЪ§ОнСПЃЌвЛАуЧщПіЯТПЩЪЕЯж2:1 ~ 3:1ЕФбЙЫѕБШЁЃ
жиИДЪ§ОнЩОГ§
дкБИЗнЁЂЙщЕЕЕШЪЕМЪЕФДцДЂЪЕМљжаЃЌШЫУЧЗЂЯжгаДѓСПЕФжиИДЪ§ОнПщДцдкЃЌМШеМгУСЫДЋЪфДјПэгжЯћКФСЫЯрЕБЖрЕФДцДЂзЪдДЃКгааЉаТЮФМўжЛЪЧдкдгаЮФМўЩЯзїСЫВПЗжИФЖЏЃЌЛЙгаФГаЉЮФМўДцдкзХЖрЗнПНБДЃЌШчЙћЖдЫљгаЯрЭЌЕФЪ§ОнПщЖМжЛБЃСєвЛЗнЪЕР§ЃЌЪЕМЪДцДЂЕФЪ§ОнСПНЋДѓДѓМѕЩйЁЊЁЊетОЭЪЧжиИДЪ§ОнЩОГ§ММЪѕЕФЛљДЁЁЃ
етвЛзіЗЈзюдчгЩЦеСжЫЙЖйДѓбЇРюПНЬЪкЃЈDataDomainЕФШ§ЮЛДДЪМШЫжЎвЛЃЉЬсГіЃЌГЦжЎЮЊШЋОжбЙЫѕЃЈGlobal CompressionЃЉЃЌВЂзїЮЊШнСПгХЛЏДцДЂЃЈCapacity Optimized StorageЃЌ COSЃЉЭЦЙуЕНЩЬвЕгІгУЁЃФПЧАЃЌГ§СЫDataDomainЕШзЈУХГЇЩЬЭтЃЌИїжївЊДцДЂГЇЩЬШчEMCЁЂIBMЁЂSymantecЁЂFalconStorЕШЕШвВЖМЭЈЙ§ЪеЙКЛђбаЗЂЕШЭООЖгЕгаСЫИїздЕФжиИДЪ§ОнЩОГ§ММЪѕЃЌгаЕФЛЙВЂЙквдБ№УћЃЌШчЕЅЪОР§ДцДЂЃЈSingle Instance RepositoryЃЌSIRЃЉЕШЁЃ
жиИДЪ§ОнЩОГ§ЕФЪЕЯжгЩШ§ИіЛљБОВйзїзщГЩЃЌШчЭМЖўЁЃЪзЯШЃЌД§ДІРэЪ§ОнЃЈЮФМўЃЉБЛЗжИюГЩЙЬЖЈЛђПЩБфДѓаЁЕФЪ§ОнПщЃЌЭЌЪБЩњГЩвЛеХЁАНсЙЙЭМЁБЯдЪОетаЉЪ§ОнПщдѕбљзщГЩЭъећЕФдЪ§ОнЃЈЮФМўЃЉЃЛШЛКѓМЦЫуИїЪ§ОнПщЕФЁАжИЮЦЁБЃЈБъЪЖЃЉЃЌВЂИљОнЁАжИЮЦЁБШЗШЯИУЪ§ОнПщЪЧЗёгыЦфЫќЪ§ОнПщЯрЭЌЃЛзюКѓЃЌЖЊЦњжиИДГіЯжЕФЪ§ОнПщЃЌВЂНЋЁАНсЙЙЭМЁБзїЮЊдЪМЪ§ОнЃЈЮФМўЃЉДцДЂЁЃ
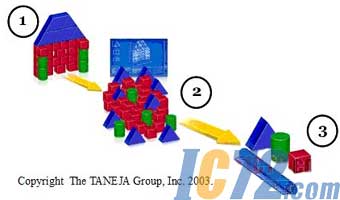
ЭМЖў жиИДЪ§ОнЩОГ§дРэ
жиИДЪ§ОнЩОГ§ММЪѕЕФЙиМќдкгкЪ§ОнПщЁАжИЮЦЁБЕФЩњГЩКЭМјБ№ЁЃЪ§ОнПщЁАжИЮЦЁБЪЧМјБ№Ъ§ОнПщЪЧЗёжиИДЕФвРОнЃЌШчЙћВЛЭЌЪ§ОнПщЕФЁАжИЮЦЁБЯрЭЌЃЌОЭЛсдьГЩФкШнЖЊЪЇЃЌВњЩњВЛПЩЛжИДЕФбЯжиКѓЙћЁЃдкФПЧАЕФЪЕМЪгІгУжаЃЌвЛАуЖМбЁдёMD5ЛђSHA-1ЕШБъзМдгДеЃЈhashЃЉЫуЗЈЩњГЩЕФЪ§ОнПщЕФеЊвЊЃЈdigestЃЉзїЮЊЁАжИЮЦЁБЃЌвдЧјЗжВЛЭЌЪ§ОнПщМфДцдкЕФВювьЃЌДгЖјБЃжЄВЛЭЌЪ§ОнПщжЎМфВЛЛсЗЂЩњГхЭЛЁЃЕЋЪЧЃЌMD5ЃЌSHA-1ЕШЫуЗЈЕФМЦЫуЙ§ГЬЗЧГЃИДдгЃЌДПШэМўМЦЫуКмФбТњзуДцДЂгІгУЕФадФмашЧѓЃЌЁАжИЮЦЁБЕФМЦЫуЭљЭљГЩЮЊжиИДЪ§ОнЩОГ§гІгУЕФадФмЦПОБЁЃ
ФПЧАЃЌИїГЇЩЬЖдИїзджиИДЪ§ОнЩОГ§ММЪѕЕФаЇгУЖМгаВЛЭЌУшЪіЃЌвЛАуЖМЩљГЦФмНЋЪ§ОнСПМѕЩйЕНдЪ§ОнЕФ3% ~ 5%ЃЌМДОпга20:1 ~ 30:1ЕФбЙЫѕБШЁЃ
Ъ§ОнбЙЫѕКЭжиИДЪ§ОнЩОГ§ММЪѕЖМзХблгкМѕЩйЪ§ОнСПЃЌЦфВюБ№дкгкЪ§ОнбЙЫѕММЪѕЕФЧАЬсЪЧаХЯЂЕФЪ§ОнБэДяДцдкШпгрЃЌвдаХЯЂТлбаОПзїЮЊЛљДЁЃЛЖјжиИДЪ§ОнЩОГ§ЕФЪЕЯжвРРЕЪ§ОнПщЕФжиИДГіЯжЃЌЪЧвЛжжЪЕМљадММЪѕЁЃетСНжжММЪѕОпгаВЛЭЌВуУцЕФеыЖдадЃЌВЂФмЙЛНсКЯЦ№РДЪЙгУЃЌДгЖјЪЕЯжИќИпЕФЪ§ОнЫѕМѕБШР§ЃЈ40:1 ~ 90:1ЃЉЁЃашвЊзЂвтЕФЪЧЃЌШчЙћЭЌЪБгІгУЪ§ОнбЙЫѕКЭжиИДЪ§ОнЩОГ§ММЪѕЃЌЮЊСЫНЕЕЭЖдЯЕЭГЕФДІРэашЧѓЃЌЭЈГЃашвЊЯШгІгУЪ§ОнЩОГ§ММЪѕЃЌШЛКѓдйЪЙгУЪ§ОнбЙЫѕММЪѕНјвЛВННЕЕЭЁАНсЙЙЭМЁБКЭЛљБОЪ§ОнПщЕФЬхЛ§ЁЃ
дкЙщЕЕгІгУжаЃЌДцДЂЕФЪ§ОнжївЊЪЧЮФМўдкВЛЭЌЪБМфЕФИїИіРњЪЗАцБОЃЌАцБОМфЕФВювьЭЈГЃВЂВЛЪЧКмДѓЃЌЮФМўжаЭљЭљгаЯрЕБвЛВПЗжФкШнВЂЮДЗЂЩњИФБфЃЌжиИДЪ§ОнЩОГ§ММЪѕвђЖјОпгаНЯДѓЕФгІгУПеМфКЭаЇФмЃЛЭЌЪБЃЌзїЮЊгаЬиЖЈвтвхЕФЮФМўФкШнЃЌЪЙгУЪ§ОнбЙЫѕММЪѕЭЈГЃвВПЩвдЛёЕУ2:1вдЩЯЕФбЙЫѕБШЁЃвђДЫЃЌеыЖдЙщЕЕгІгУЃЌМЏГЩжиИДЪ§ОнЩОГ§КЭЪ§ОнбЙЫѕММЪѕНЋПЩДјРДЯджјЧвПЩвддЄЦкЕФКУДІЃЌЪЕЯж90%вдЩЯЕФећЬхЪ§ОнСПЫѕМѕЁЃ
ашвЊзЂвтЕФЪЧЃЌгЩгкЪ§ОнбЙЫѕКЭжиИДЪ§ОнЩОГ§ММЪѕЖМЯЕЭГДІРэФмСІгаНЯИпвЊЧѓЃЌЮЊСЫБЃжЄећЬхадФмЃЌдкдЄЫудЪаэЕФЗЖЮЇФкЃЌгІИУзЂвтбЁдёОпгаЯрЙигВМўМгЫйЕФЗНАИЁЃФПЧАЃЌЪаГЁЩЯФмЙЛЭЌЪБОпгабЙЫѕКЭдгДеЫуЗЈЕФНтОіЗНАИВЂВЛЖрЃЌжївЊгЩLZSЫуЗЈЕФзЈРћгЕгаепHifn, IncЬсЙЉЁЃГ§СЫГЃМћЕФБъзММгУмКЭеЊвЊЫуЗЈЃЌHifnЕФАВШЋДІРэЦїКЭЯргІМгЫйПЈЛљБОЖММЏГЩгабЙЫѕДІРэФмСІЃЌЬсЙЉ20MB/s ~ 250MB/sЕФДІРэФмСІЁЃзюНќЛЙзЈУХЭЦГіСЫDR 250/255Ъ§ОнЫѕМѕМгЫйПЈЃЌЭЈЙ§PCI-XКЭPCI-ExpressНгПкЮЊДцДЂЯЕЭГЬсЙЉ250MB/sЕФЪ§ОнбЙЫѕКЭеЊвЊМЦЫуМгЫйЃЌВЂФмЙЛЭЌЪБНјааМгУмЛђНтУмДІРэЃЌЪЙЯЕЭГФмЙЛдкЪЕЯжЪ§ОнЫѕМѕЕФЭЌЪБЃЌЬсИпЖдЪ§ОнЕФБЃЛЄМЖБ№ЁЃОнГЦЃЌHifnЯТвЛДњЪ§ОнЫѕМѕВњЦЗДІРэФмСІНЋДяЕН1.6GB/sЃЌВЂжЇГжIEEE P1619/1619.1БъзМЕФДХХЬ/ДХДјМгУмЃЌМЦЛЎНЋгкНёФъЯТАыФъе§ЪНЭЦЯђЪаГЁЁЃ |