直接存储器存取(DMA)控制器是一种在系统内部转移数据的独特外设,可以将其视为一种能够通过一组专用总线将内部和外部存储器与每个具有DMA能力的外设连接起来的控制器。它之所以属于外设,是因为它是在处理器的编程控制下来执行传输的。值得注意的是,通常只有数据流量较大(kBps或者更高)的外设才需要支持DMA能力,这些应用方面典型的例子包括视频、音频和网络接口。
一般而言,DMA控制器将包括一条地址总线、一条数据总线和控制寄存器。高效率的DMA控制器将具有访问其所需要的任意资源的能力,而无须处理器本身的介入,它必须能产生中断。最后,它必须能在控制器内部计算出地址。
一个处理器可以包含多个DMA控制器。每个控制器有多个DMA通道,以及多条直接与存储器站(memory bank)和外设连接的总线,如图1所示。在很多高性能处理器中集成了两种类型的DMA控制器。第一类通常称为“系统DMA控制器”,可以实现对任何资源(外设和存储器)的访问,对于这种类型的控制器来说,信号周期数是以系统时钟(SCLK)来计数的,以ADI的Blackfin处理器为例,频率最高可达133MHz。第二类称为内部存储器DMA控制器(IMDMA),专门用于内部存储器所处位置之间的相互存取操作。因为存取都发生在内部(L1-L1、L1-L2,或者L2-L2),周期数的计数则以内核时钟(CCLK)为基准来进行,该时钟的速度可以超过600MHz。
每个DMA控制器有一组FIFO,起到DMA子系统和外设或存储器之间的缓冲器的作用。对于MemDMA(Memory DMA)来说,传输的源端和目标端都有一组FIFO存在。当资源紧张而不能完成数据传输的话,则FIFO可以提供数据的暂存区,从而提高性能。
因为你通常会在代码初始化过程中对DMA控制器进行配置,内核就只需要在数据传输完成后对中断做出响应即可。你可以对DMA控制进行编程,让其与内核并行地移动数据,而同时让内核执行其基本的处理任务―那些应该让它专注完成的工作。

图1:系统和存储器DMA架构。
在一个优化的应用中,内核永远不用参与任何数据的移动,而仅仅对L1存储器中的数据进行读写。于是,内核不需要等待数据的到来,因为DMA引擎会在内核准备读取数据之前将数据准备好。图2给出了处理器和DMA控制器间的交互关系。由处理器完成的操作步骤包括:建立传输,启用中断,生成中断时执行代码。返回到处理器的中断输入可以用来指示“数据已经准备好,可进行处理”。

图2:DMA控制器。
数据除了往来外设之外,还需要从一个存储器空间转移到另一个空间中。例如,视频源可以从一个视频端口直接流入L3存储器,因为工作缓冲区规模太大,无法放入到存储器中。我们并不希望让处理器在每次需要执行计算时都从外部存储读取像素信息,因此为了提高存取的效率,可以用一个存储器到存储器的DMA(MemDMA)来将像素转移到L1或者L2存储器中。
到目前为之,我们还仅专注于数据的移动,但是DMA的传送能力并不总是用来移动数据。我们可以用代码覆盖的办法来提高性能,将DMA的控制器配置为在执行前把代码送入L1指令存储器。代码往往存储于较大的外部存储器中,而根据需要有选择性的送入L1。
DMA控制器的编程
让我们考察一下在定义DMA活动的过程中可以有哪些选项。我们将从最简单的模型开始,并在此基础上过渡到更为灵活的模型,这反过来增加了设置的复杂度。
对于任何类型的DMA传输,我们都需要规定数据的起始源和目标地址。对于外设DMA的情况来说,外设的FIFO可以作为数据源或者目标端。当外设作为源端时,某个存储器的位置(内部或外部)则成为目标端地址。当外设作为目标端,存储的位置(内部或者外部)则成为源端地址。
在最简单的MemDMA情况中,我们需要告诉DMA控制器源端地址、目标端地址和待传送的字的个数。采用外设DMA的情况下,我们规定数据的源端或者目标端,具体则取决于传输的方向。每次传输的字的大小可以是8、16或者12位。这种类型的事务代表了简单的1维(“1D”)统一“跨度”(unity stride)的传输。作为这一传输机制的一部分,DMA控制器连续跟踪不断增加的源端和目标端地址。采用这种传输方式时,8位的传输产生1字节的地址增量,而16位传输产生的增量为2字节,32位传输则产生4字节的增量。上面的参数是基本的1D DMA传输的设置参数。
我们只需要改变数据传输每次的数据大小,就可以简单地增加一维DMA的灵活性。例如,采用非单一大小的传输方式时,我们以传输数据块的大小的倍数来作为地址增量。也就是说,若规定32位的传输和4个采样的跨度,则每次传输结束后,地址的增量为16字节(4个32位字)。
虽然1D DMA得到了广泛的应用,但用处更大的则是2维(2D) DMA,特别是在视频应用中。2D功能是我们所讨论的1D DMA的情形的一种直接扩展。除了XCOUNT和XMODIFY值之外,我们还需对对应的YCOUNT和YMODIFY值进行编程设定。2D DMA可以简单地理解为一个嵌套的循环,即内循环由XCOUNT和XMODIFY来规定,外循环由YCOUNT和YMODIFY规定。一个1D DMA可以被简单的视为2D传输的“内循环”,如下形式:
for y = 1 to YCOUNT /* 2D的外循环*/
for x = 1 to XCOUNT /* 1D的内循环 */
{
/* 传输循环主体转移到这里 */
}
XMODIFY决定了XCOUNT每次减少时的DMA控制器的跨度值,而YMODIFY则决定了YCOUNT每次减少时对应的跨度值。与XCOUNT和XMODIFY一样,YOUNT可以以传输数量来定义,而YMODIFY则以字节数来定义。值得注意的是,YMODIFY可以为负值,这会让DMA控制器回转到缓冲器的起始点。
对于外设DMA来说,传输的“存储器端”可以是1D或2D。不过,在外设端,传输始终是1D的。唯一的限制是在DMA每一端(源端和目标端)传输的字节总数必须相同。例如,如果我们从3个10字节的缓冲器向外设馈入数据。例如,如果我们从3个10字节的缓冲器向外设发送数据,外设必须被设定为传送30字节,具体方式则可以是任何可能的、所支持的传输宽度和传输计数值的组合。
MemDMA提供的灵活度则要更高一些。例如,如果我们可以建立一个1D-2D传输、一个1D-2D传输、1个2D-1D传输,且可自然而然建立一个2D-2D传输,唯一的限制条件是,在DMA传输模块的两端所传送的字节总数必须相等。
DMA的设置
目前有两类主要的DMA传输结构:寄存器模式和描述符模式。无论属于哪一类DMA,表1所描述的几类信息都会在DMA控制器中出现。当DMA以寄存器模式工作时,DMA控制器只是简单地利用寄存器中所存储的参数值。在描述符模式中,DMA控制器在存储器中查找自己的配置参数。

表1:DMA寄存器
基于寄存器的DMA
在基于寄存器的DMA内部,处理器直接对DMA控制寄存器进行编程,来启动传输。基于寄存器的DMA提供了最佳的DMA控制器性能,因为寄存器并不需要不断地从存储器中的描述符上载入数据,而内核也不需要保持描述符。
基于寄存器的DMA由两种子模式组成:自动缓冲(Autobuffer)模式和停止模式。在自动缓冲DMA中,当一个传输块传输完毕,控制寄存器就自动重新载入其最初的设定值,同一个DMA进程重新启动,开销为零。
正如我们在图3中所看到的那样,如果将一个自动缓冲DMA设定为从外设传输一定数量的字到L1数据存储器的缓冲器上,则DMA控制器将会在最后一个字传输完成的时刻就迅速重新载入初始的参数。这构成了一个“循环缓冲器”,因为当一个量值被写入到缓冲器的最后一个位置上时,下一个值将被写入到缓冲器的第一个位置上。
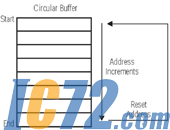
图3:用DMA实现循环缓冲器。
自动缓冲DMA特别适合于对性能敏感的、存在持续数据流的应用。DMA控制器可以在独立于处理器其他活动的情况下读入数据流,然后在每次传输结束时,向内核发出中断。虽然有可能以恰当的方式阻止自动缓冲模式,但如果DMA进程需要定期启动和停止时,采用这种工作方式就没有什么意义。
停止模式的工作方式与自动缓冲DMA类似,区别在于各寄存器在DMA结束后不会重新载入,因此整个DMA传输只发生一次。停止模式对于基于某种事件的一次性传输来说十分有用。例如,非定期地将数据块从一个位置转移到另一个位置。当你需要对事件进行同步时,这种模式也非常有用。例如,如果一个任务必须在下一次传输前完成的话,则停止模式可以确保各事件发生的先后顺序。此外,停止模式对于缓冲器的初始化来说非常有用。
描述符模型
基于描述符(descriptor)的DMA要求在存储器中存入一组参数,以启动DMA的系列操作。该描述符所包含的参数与那些通常通过编程写入DMA控制寄存器组的所有参数相同。不过,描述符还可以容许多个DMA操作序列串在一起。在基于描述符的DMA操作中,我们可以对一个DMA通道进行编程,在当前的操作序列完成后,自动设置并启动另一次DMA传输。基于描述符的方式为管理系统中的DMA传输提供了最大的灵活性。
ADI 的Blackfin处理器上有两种主要的描述符方式―描述符阵列和描述符列表,这两种操作方式所要实现的目标是在灵活性和性能之间实现一种折中平衡。
在描述符阵列模式下,描述符驻留在连续的存储器位置上。DMA控制器依然从存储器取用描述符,但是因为下一个描述符紧跟着当前的描述符,说明到何处去寻找下一个描述符(以及它们相应的描述符取用)的两个数据字就并不必要。因为描述符并不包含这一“下一描述符”指针项,DMA控制器希望一组描述符在存储器相互挨在一起,如同阵列一般。
当各描述符在存储器中的分布位置并非“背对背”时,可以使用一个描述符列表。实际上这里涉及多种子模式,从而再一次实现了性能和灵活性之间的折中平衡。在“小描述符”模型中,描述符包括了一个单16位的域,用来给出“下一描述符指针”域的低位部分;高位部分则通过寄存器来独立编程设定,并且不发生改变。当然,这将描述符限制在存储器中一个特定的64K(=216)页面上。当描述符的位置需要跨越这一边界时,也可以提供一个“大”模型,它可以为“下一描述符指针”项提供32位的位置。
无论采用何种描述符模式,描述符的量值数越多,则描述符取用的次数就越多。这也就是为何Blackfin处理器定义了一个“柔性描述符方式”的原因,该模式可以修改描述符的长度,使之仅仅包括特定传输所需要的数据。例如,如果不需要2D DMA,YMODIFY和 YCOUNT 寄存器就不需要成为描述符数据块的一部分。
描述符管理
管理描述符列表的最佳方法是什么?其实,这个问题的答案需要根据应用来定,但要明白存在何种替代方法很重要。
我们将描述的第一种选择,其工作方式非常类似于一个自动缓冲DMA。它需要设定多种描述符,并将其串连到一起,正如图4a所示的那样。“串连”一词意味着一个描述符指向下一个描述符,描述符的载入是自动的。为了使链条完整,最后一个描述符反向指向第一个描述符,于是整个流程就重复下去。使用这种技术而不是自动缓冲的一个理由就是,这些描述符可以保证传输的规模和方向上具有更大的灵活性。

图4:由处理器进行调控的DMA描述符:(a)链接的描述符列表;(b)“节流调节式”的描述符管理。
第二个选择则是由处理器来管理描述符列表。回想一下,描述符实际上是存储器中的一个结构,每个描述符包含了一个配置字。每个配置字包含了“使能”位,其作用是在传输开始时进行调节。如果我们需要让处理器在做好准备时去启动每次具体的传输,我们就可以事先设定好所有的描述符,但把“使能”位清零。当处理器确定启动描述符的时机已经到来时,它只需简单地更新存储器中的描述符,然后写入DMA寄存器中,以让处于停止状态的通道启动起来。图4b示出了这一流程的一个例子。
这种类型的传输什么时候有用呢?请考虑一个需要将输入流与输出流实现同步的多媒体应用。例如,我们接收视频采样,将其传输到存储器的速率可能会不同于将该视频输出显示的速度。在实际系统中,即使你试图让流以恰好相同的时钟传输,也会发生这种情况。在同步成问题的情况下,处理器可以调整对应于输出缓冲器的DMA描述符。在下一个描述符启用时,处理器可以通过调整目前的输出描述符来实现流的同步,具体方式是利用一种信号量机制(semaphore mechanism)来确保每次只有一个项访问共享资源。
在处理器之间使用内部的DMA描述符链或者基于DMA的流时,一种有用的做法是在所传输的数据块的末尾添加一个额外的字,用以帮助标识正被发送的包,包括关于应该如何处理数据的信息和时间戳。图4b中虚线所划出的区域则示出了这种方案。
大多数成熟的应用都有以软件形式实现的“DMA 管理器”功能。这可以作为操作系统或者实时内核的一部分来提供,但它也可以在没有这两者的条件下运行。在Blackfin处理器上,该功能可以作为VisualDSP++工具包的‘System Services’的一部分提供。这一管理功能可以让你通过标准的API来转移数据,而不必手工去配置每一个控制寄存器。
基本上,一个应用将DMA描述符的要求提交给DMA队列管理器,其责任是处理每一次请求。请求的处理则是按照它们被应用软件接收到的顺序来进行的。指向“回调”函数的地址指针往往也是系统的一部分。该函数可以完成在数据缓冲准备好时你希望处理器来完成的工作,无需让内核停留在高优先级的中断服务例程的执行中。总的来说,DMA管理器可以简化编程模型,因为它对数据的传输进行了抽象。
管理采用中断的描述符队列可以有两种通用的方法:第一种基于在每次描述符完结时所发出的中断,只有当你能确保每个中断事件将单独得到服务、无中断溢出时,才使用这种方法;第二种方法是仅仅在由一个工作块的最后一个描述符所规定的工作传输结束时发出中断。工作块是一个或者多个描述符的集合。
为了保持描述符队列的同步,非中断型软件就必须维持一个添加到队列中的描述符数量的计数,而中断处理程序则维持一个对已完结的、从队列中除去的描述符的计数。计数次数仅仅在DMA完成对所有的描述符的处理后暂停时才会相等。
本文小结
本文中,我们讨论了DMA数据流的结构:基于寄存器的和基于描述符的,以及何时使用其中的某种结构。在下一期中,我们将分析某些先进的DMA功能特色,这些功能将协助数据在多媒体系统中有效地移动。 |