在嵌入式装置中建置多核心(包含同质或异质)以及多执行绪技术,的确能带来诸多效益,尤其是改进系统效能方面最为明显。
尽管RISC嵌入式技术所面临的挑战越来越多,但是在维持以往嵌入式软件资源兼容性的前提之下,能够改善其未来适用性,并且有效提升新系统的效能表现,使其不失为良好的解决方案。
应用决定多核或多绪
多核心与多执行绪在效能表现上有其帮助,但是效能与这些技术的内建其实并没有绝对关系,会造成这样的原因主要是应用环境的需求。以手机为例,整合于手机内的SoC芯片虽然是属于多核心架构的一环,但是手机采用的SoC芯片多为应用处理器,其整合的核心并非完全属于同性质架构,同质多核心在嵌入式系统实际应用上的案例其实非常少。
而多执行绪处理器在汽车电子或者是嵌入式网络环境中扮演着重要的角色,但是也有厂商利用数颗多执行绪芯片组成多核心与多执行绪兼备的运算架构,换句话说,两者并不是单纯选边站而已,根据实际应用的需求,自行搭配或开发最终解决方案也成了许多厂商面对问题时的态度。这也代表着,在选择嵌入式系统的基础架构时,处理器本身只是应用的1个环节,如何能够针对应用将所需的效能最大化,必须依照产品的不同而有各种考虑。
不只是意气的技术之争
真正的同质多核心架构-ARM11 MPCore
在嵌入式多核心应用处理器这方面的领域,目前以ARM为技术领导者,虽然该公司本身并无晶圆厂,而纯粹以IP的形式出售处理器架构,由于定位正确,在短短的数年间取得了极大的市场地位,全世界绝大多数的手持式装置都嵌入了ARM的处理器技术。
以其技术的发展历程来看,早期的ARM7架构本身能够满足一些音效编译码应用。而在增加16位饱和运算指令和提高ARM9核心速度后,不仅能完成音效编译码工作,以及以大约80 MHz、15 画格/秒速度下的MPEG-4 QCIF(4分之1 CIF分辨率)编码。在ARM11 V6指令集架构上增加速度和SIMD指令后,就可以实现VGA分辨率的 H.264 编码。再进一步到最新的Cortex A8与其基于64位SIMD架构的Neon加速器搭配工作之下,就可以完成 30 画格/秒的 MPEG-4 VGA 编码,所花周期只有 ARM11 的一半。在实际情况下,该工作需要大约 300 MHz。为了使这些选项对使用者更加可行,ARM 正在开发一个并行编译器原型,它可以提取资料并行机制,并用 SIMD 硬件来使用它
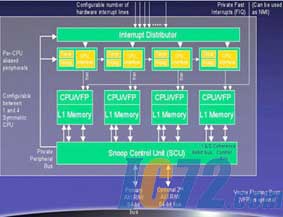
图1:ARM11 MPCore的结构示意图。
ARM11 MPCore乃是在ARM11核心的基础组成,架构上属于V6指令体系。根据不同应用的需要,MPCore可以被配置为1∼4个处理器的组合方式,根据官方表示,其最高性能约可达到2600 Dhrystone MIPS的程度。MPCore是标准的同质多核心处理器,,组成MPCore的是4个基于ARM11架构的处理器核心,由于多核心设计的优点是在频率不变的情况下让处理器的性能获得明显提升,因此可望在多任务应用中拥有良好的表现,这一点很适合未来家庭消费电子的需要。例如,机上盒在录制多个频道电视节目的同时,还可通过因特网收看数字视讯点播节目、车内导航系统在提供导航功能的同时,仍然有余力可以向后座乘客播放各类视讯娱乐串流等。
在这类应用环境下,多核心结构的嵌入式处理器能够表现出极强的性能优势。根据原厂数据,MPCore多处理器可支持高达4路共享快取结构的对称多处理器 (four-way cache coherent symmetric multiprocessing,SMP)、或者是4路不对称多处理器(four-way asymmetric multiprocessing,AMP)以及4路兼有对称/不对称的混合式多处理器系统。其设计的高灵活设计在理论上可以满足各种跨领域应用对运算性能的弹性需求,确保系统可获得一流的响应能力或数据吞吐量。
不过ARM11 MPCore早在2004年就已经发布,2005年正式加入授权业务,截至目前为止,采用该处理器的产品集中于家电与汽车电子方面,但是数量并不算多,是业界对于处理器运算能量的需求尚未显现?据了解,在汽车电子方面,汽车应用的微处理器要求越来越高,但是过去的单核心基本上还能满足一般汽车的使用,而随着越来越多的电子辅助装置整合进汽车中,其间所需处理的工作也越来越繁杂,已经远超过传统汽车用微控制器所能负担的程度,因此可预期的是,未来数年应该会有越来越多汽车厂商采用类似的多核心架构来取得合理的系统反应速度。
至于在家电应用方面,其实需要用到如此复杂核心的产品不多,在应用最多的影音产品方面,其实大部分的厂商都采用专用的硬件译码电路或者是DSP来进行编译码的动作,直接采用多核心处理器来进行编译码动作其实效益不明显。而在移动应用方面,其实功耗依然是移动产品厂商所最注重的,即便ARM11 MPCore能够达到极低的多核心同时工作功耗,但是依然无法与单核心版本相比,因此在移动应用上能见度不高。但是随着Intel推行MID(Mobile Internet Device),类似的产品可望成为ARM11 MPCore架构的极大机会,因为即便是Stealey的下一代45nm产品Silverthorne,其功耗依然比MPCore高了5倍以上(加上芯片组的总功耗),且仅为单核心架构,在应用灵活度上明显不如MPCore架构,不过有1点值得注意的是,Silverthorne挟带了庞大的X86软件资源,ARM等基于RISC体系处理器在这方面要明显屈居于下风。
在RISC架构的类MID产品上,也可以考虑ARM最新的处理器架构,也就是Cortex-A8,该处理器基于最新的ARM v7体系,并且整合了1个64位DSP处理单元,对串流应用具备有极佳的加速能力,因此非常适用于类MID掌上型装置的多媒体、甚至是游戏应用。严格上来说,Cortex-A8也能算是多核心体系之一,但是其架构与MPCore之类的同质核心不同,而是采用1个通用处理器核心,并搭配个DSP核心而成的异质多核心处理器,相信这方面ARM向德州仪器公司借鉴了不少应用处理器的开发经验。
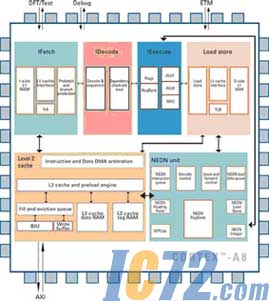
图2:Cortex-A8的结构示意图。
事实上,NOKIA的N770/N800便已经具备了MID的所有功能,而且更为轻薄短小,但遗憾的是,搭配原厂的1500mAh充电电池,其持续使用时间仅能达到3.5个小时,与一般市面上的UMPC产品相去不远,稍逊于Intel的MID产品,采用ARM体系处理器(N800采用基于ARM1136J(F)-S核心的i.MX31应用处理器)的省电优势在此并没有被凸显出来,不过待机时间比之MID要略长。
坚持多执行绪路线的MIPS
或许可以视为意气之争,MIPS坚持与ARM实行不同的技术发展策略,ARM发展Multi Processor(MP,多处理器核心),而MIPS则往Multi Thread(MT,多执行绪)发展,就应用概念上来看,MP与MT技术两者均致力于提高处理器的整体性能,两者都可以减少任何应用当前软件执行绪的处理时间。但这两种技术采用了不同的硬件结构来减少处理时间,因此对于任意的特定软件程序代码来说,MP与MT对处理器性能的提升着程度上的不同。
但是会造成这样的结果,其实2家IP厂商的研发概念上有很大的关连。由于MT技术着重于处理单元、内存控制器的有效利用,在最大程度上节省晶体管的使用,并且在此前提之下往上提升效能表现,这与MP架构中,系统效能需求有多少,就复制多少个核心塞进芯片中的浪费作法完全不同,MP可以取得较为全面的应用广度,但是稍嫌铺张浪费,相较之下,MT在成本与效能方面的平衡性表现要来得高明些。
许多人将MP与MT相提并论,而在某种程度上,这样的比较其实并没有太大意义,因为基本设计概念已经天差地远,架构上的采用自然无法一概而论。在技术上,为了实现硬件多重处理,两者对于软件最佳化的复杂度方面其实都同样比单核心架构要来得复杂许多,而为了要尽量避免处理单元与内存控制器在资源分配上的冲突,MT架构或许会来得更为复杂一些,但MP架构其实在某些程度上也会面临同样的问题(特别是共享高速缓存与内存控制器的多核心架构)。不论是在指令层级,或是执行绪层级的多任务,都与传统单核心单执行绪的程序写作方式与最佳化方法大异其趣。
一般的MT架构设计方面,单一处理器核心在运算的过程中,常会有内存存取速度跟不上处理器频率增加的问题,进而导致高速缓存错失(miss)时,形成执行管线长时间闲置的状况,我们都了解,1个系统中的储存单元,最快速的要属处理器中的缓存器,其次是L1高速缓存、L2快取记体,最后则是主存储器,其速度的差别可达数千倍以上,处理器要取得指令或数据时,必先从高速缓存中提取,储存于缓存器中进行运算,最终结果再回存到高速缓存,并在空闲时填回主存储器,当处理器向高速缓存发出存取需求,却发现所需要的数据不在高速缓存中,这是就必须花费大笔的时间前往主存储器寻找并读取,这其间所浪费的时间可能会高达数十个频率周期,处理管线在等待数据填补的时间,就形成了闲置状态。
如果利用多执行绪处理概念,适时的将其它执行绪拉过来填补已经造成的闲置状态,其速度的增长甚至可以达到非常明显的地步,虽不至于倍增,但是由20%到40%都有可能。而要达成这样的目的,在晶体管数目方面只需增加约15%的程度即可,若以一般同样架构的单核心处理器在变更为双核心的效能增长程度约为40%到70%左右的程度,而晶体管数目几乎要倍增的情况,就可看出MIPS的MT技术的效率有多高了。但是MT技术有个严重的缺陷,那就是多执行绪工作处理过程中,过于频繁的上下文切换(context switch)将有可能会造成极大的效能耗损。
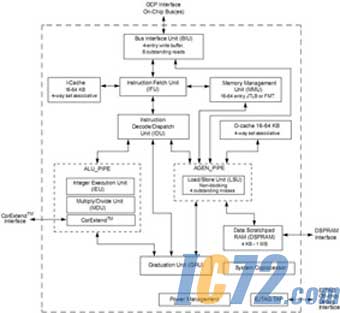
图3:MIPS 74K处理器结构示意图。
MIPS公司有大产品线,分别是单执行绪的24K与74K系列,以及多执行绪的34K系列。74K甫于今年六月发表,在65nm工艺下,其运作频率已经超越1GHz,采用通用处理器搭配DSP核心的设计,不过总体效能与功耗表现略逊于类似架构的ARM Cortex-A8。多执行绪处理器的主角―34K系列,该处理器核心能设定1或2个虚拟处理组件(VPE)以及最多5个执行绪内容(TC),提供充分的可配置弹性。但是讲白了,其实两个VPE的作法就是将单颗核心模拟为2个核心,使34K核心能同时执行两个独立的操作系统,或是一个双路的对称式多重处理器操作系统。
MIPS32 34Kc核心采用90nm工艺,最差操作状态下频率为500MHz。核心尺寸为2.1mm2,而核心部分耗电量为0.56mW/MHz@1.0V。目前该 系列核心共包含34Kc、34Kf、34Kc Pro以及34Kf Pro。这些核心具备完全兼容于IEEE 754规格的硬件浮点运算处理器。其中34Kc Pro与34Kf Pro核心具备CorExtend功能,能让SoC研发业者自行扩增指令。
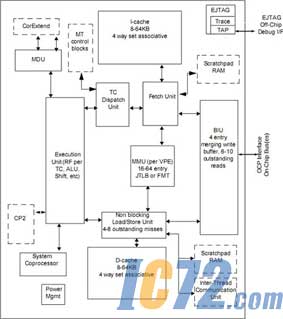
图4:MIPS 34K处理器结构示意图。
根据MIPS自家的估算,与同家族的24K系列产品相较起来,34K在2个VPE以及2个TC的组态设定之下,可以将效能提升到超越24K处理器60%的程度,芯片面积大略增加14%,而因为多执行绪作业所导致的高速缓存失误比率则是由4.41%增加到5.16%,算是在可接受的范围之内。
不过与单核心74K相较起来,34K反而更不适用于网络或多媒体串流的密集计算环境,而VPE和TC单元的增加,同样也会加大芯片的面积。虽说MT技术的局限性,使其不适合用于多媒体编译码应用上,但是在汽车电子方面,已经有厂商成功利用2颗34K处理器组成双核多执行绪处理器,并提供的相当优秀的执行效能,有此成功的前例可循,我们也可以预测,未来MIPS将会有更多结合多核与多执行绪的解决方案出现,不过这么一来,在成本调配方面的优势还能剩下多少,就由方案提供厂商去伤脑筋吧。 |