1 引言
脉冲压缩技术已经广泛应用于各种现代雷达中,他采用大时宽的发射脉冲以提高发射信号的平均功率,保证了足够的探测距离,而在信号接收时采用脉冲压缩方法获得窄脉冲输出,从而提高了距离分辨力,一定程度上解决了雷达作用距离和距离分辨力之间的矛盾。脉冲压缩技术的关键在于他应用了调频或调相等脉冲信号,使信号具有满足雷达性能要求的时宽带宽积。脉冲压缩处理通常按匹配滤波,旁瓣抑制滤波两步进行。旁瓣抑制滤波是因为匹配滤波输出的旁瓣比较高,不利于目标识别。旁瓣抑制滤波就是对匹配输出进行加权处理,以提高主旁瓣比。脉压处理可以分时域和频域两种实现方式,其原理如图1所示。
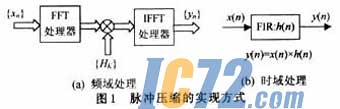
从算法上考虑,匹配和加权滤波器可以合二为一。即脉冲压缩的系统冲击响应就是匹配和抑制2个冲击响应的卷积,且是一个有限冲击响应滤波器。时域处理是采用模拟滤波器或数字FIR滤波器进行卷积运算,前者是传统FIR滤波器实现。频域方式是用专用FFT芯片或通用DSP芯片把卷积运算通过FFT-乘-IFFT组合运算完成。比较而言,时域处理对较长时宽信号的设备量要求较大。频域处理对不同时宽信号具有较强的适应能力、可编程,处理灵活。本方案采用频域方法实现。
2 频域脉压处理实现分析
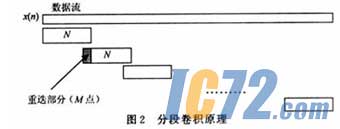
数字脉压系统,设输入序列x(n)、输出y(n)、系统冲击响应h(n)。系统时域处理为y(n)=x(n)h(n)运算。对于频域处理,其运算为:y(n)=IFFT{FFT[x(n)]FFT[h(n)]},其中FFT()和IFFT()分别指N点的快速傅里叶变换和逆变换①。即,输入信号序列按N点一组分段在频域中做循环卷积。目标回波信号可能出现在分段跨接处,所以必须采用重迭分段卷积运算以免丢失目标,其原理如图2所示。至于重迭宽度,应视雷达脉冲信号的宽度而定。本系统中信号宽度最大不超过42μs,对应6.6 MHz的采样率分段重迭点为280。
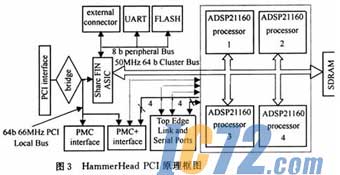
对实时运算系统,数据传输及运算都应在规定的时间内完成,即系统需要一个高效的数据输入/输出通道和一个并行的处理模块。当然,系统数据输入/输出及处理能力与具体系统相关。本系统对I,Q两路接收信号进行6.6MHz采样,采用12bA/D。对于频域脉压,读入数据按N点一组做FFT及IFFT运算,且一组数据完全读入时才能开始脉压运算,于是频域脉压就存在一个延时,即等待数据块到齐以及数据处理完毕才能最后输出,不同于时域脉压每输入一个样点就产生一次输出(数据流处理方式)。对于实时处理系统,需首先考虑块数据的处理时间Tc≤L•Tx,其中Tx是采样间隔时间,L是数据块的长度;其次数据传输速度至少要大于采样速度。如果采用N=1024的FFT运算单元,重叠部分为M=280,则输入数据块为N-M=744点。由上述原则,可以得到该实时系统对处理器和数据传输能力的要求。6.6MHz的采样率下Tc≤L•Ts=744/6.6111.6μs,即要求系统能在110μs完成2个1024点的FFT和一组1 024点的复数乘运算。现有通用DSP计算时间一般都不能满足这个要求,但采用多处理器并行工作可解决运算能力问题。综上考虑,选用Bittware公司的通用DSP信号处理板HammerHead PCI,这是一块拥有4个DSP的数字信号处理板,单片DSP的FFT处理时间约为125μs(80MHz core clock);DSP之间通过64b的cluster bus紧耦合,互联的链路口(Link port)可以提供相互独立的松耦合的数据通道,处理板原理见图3所示。脉压系统的原理可如图4所示。
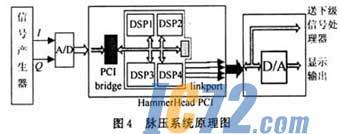
3 基于DSPs的频域脉压实现
确定硬件平台后,便可进行算法映射。如前所述,本系统的工作包含数据处理和数据传输2个方面,数据传输为数据处理提供及时可用的数据以及计算结果输出,数据处理是循环往复地对每一块数据进行脉压运算。对于信号处理板及DSP,数据块的传输均可采用DMA方式,这样的优点是传输不占用处理器核的时间①,只需要处理器核做DMA的配置工作。于是数据传输和数据处理可以从物理和逻辑上分开,两者并行工作,且仅通过约定的软件接口及中断触发机制相联系。由上分析,在实现脉压处理控制时可把软件设计分为数据传输层和数据处理层两部分(当然形成系统时还需要增加控制层)。这两层的接口就是数据读入和输出的数据缓冲区,中断信号可使两层同步运行。
在传输和处理分开考虑的前提下,首先讨论数据传输。即为数据处理提供完整的数据通道,使数据处理部分只需从约定的内存区域获取输入数据,把处理结果存放到相应的位置,这可降低程序编写难度并能获得较高的稳定性、可读性。对于频域处理,当数据块完全读入才能开始运算,因此数据传输采用块传输方式,反之若每得到一个采样点就传输一次,系统效率将大大降低,发生总线冲突的可能性会更大。对6.6MHz的采样率,完成744点数据块的采样需要111.6μs,而集中传输仅需15μs,即总线有86.5%的空闲率,这使总线上各片控制信号发生碰撞的机率大为减少。块采样结束时A/D产生一个窄脉冲信号。每片DSP都可以选择此信号作中断源,在块采样结束时控制处理板上的ASIC启动DMA接收这段数据。脉压运算主要是FFT运算②,一组数据的FFT可由一片DSP完成也可由4片共同完成。由FFT的信号流图[3]可知,对于N点FFT,可先在4个DSP上分别完成4个N/4点FFT,然后将结果交织完成N点FFT最后阶段的运算,这样需要在片间交换数据,引入片间数据等待时间。另一种处理方式是由4片DSP分别独立计算N点FFT,并轮流输出结果,我们称之为多片流水处理。相对前者,流水处理避免了片间数据等待,有较高的系统运算效率,缺点是成倍增加系统输出时延(相对数据块采样完成)。流水处理的系统输出时延为:tr+tc+tp+to,而前者为:tr+tc/2+tov+tp/4+to(其中tr,tc,tp,tov,to分别是输入传输、格式转换、脉压处理、交织数据传输以及数据输出的时间),可见流水方式运算效率即CPU利用率较高①,因此本方案采用流水并行方式。
A/D输出的数据是两路合一的,即低16位为I路的采样值,高16位为Q路采样数据,格式为二进制补码形式。这样的数据格式使传输时间减少一半,只是需要在数据接收到DSP时做格式转换,即分别截取I,Q两路数据并转换成浮点存放到各自的接收缓冲区。出于程序模块化考虑,将格式转换的程序放到数据传输部分,这样数据处理部分就只做与脉压相关的运算。
综上所述,脉压软件可以分为数据传输部分和数据处理部分。对于数据接收,利用一片DSP作主控,当A/D完成块数据块采样并发出中断信号时,主控DSP进入中断服务程序并启动相应DSP的数据接收DMA,之后退出中断服务继续本片DSP的工作。而相应DSP在接收DMA结束时进入自己的中断服务程序完成数据格式转换并返回。至此数据传输部分工作完成。对于某一片的数据处理也是一块数据完全读入再开始新一轮远算。脉压系统软件流水时序如图5所示。各片DSP的内存组织及数据流向如图6所示。
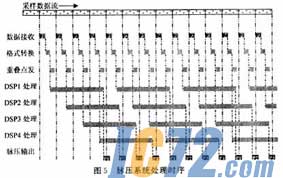
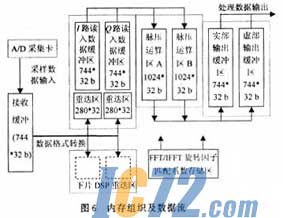
最后讨论实时处理的一些条件。首先,由于系统的DMA接收通道有限(这里为1),在本文的处理方式下,数据读入必须在下一块数据开始传输之前完成,即在111.6μs内完成744×32b数据的读入。其次,4片流水处理机制决定数据处理(包括格式转换)的最大时间限制为:111.6×4μs。数据输出通道的速度要求与系统和下一级处理器的连接方法有关,这里暂不讨论。所以不包括输出时间,脉压系统的输出最大延时为111.6×5μs,当然工程上必须留有足够的时间余量来进行系统控制、容错处理以及可能出现的其他扩展,本系统的延迟时间约390μs,其中处理时间354μs。
4 结语
实时并行系统的前期算法分析和体系结构映射方案十分重要,良好的框架可以让复杂的算法高效可靠的实现,也可以让软件更容易实现模块化从而减小开发周期。本文谈到的算法分析及实现方法现已应用于实际工程项目中,并且获得了良好的系统性能和稳定性。对各种时宽和信号形式(时宽在几到几十μs之间,信号形式包含相位编码、非/线性调频)的雷达模拟回波信号,实测脉压输出波形与Matlab仿真结果基本吻合,主旁瓣比仅差3 dB左右。 |