1 引 言
随着因特网的迅速发展,Web在人们的日常生活和工作中的地位日益显著。Web中包含页面的内容信息、超链接信息,以及Web页面的访问和使用信息,如何针对这些信息,应用数据挖掘技术挖掘出有用的信息,更好地为用户服务,已经成为目前国内外的一个新的研究热点。在Internet中,对于特定的网站而言,其页面之间的拓扑结构是已知的。尽管不同的用户在不同时期可能会有不同的浏览模式,但长期趋势应该是稳定的。因此,挖掘特定网站一定时期内用户的访问信息,便可以发现该网站的相似用户群体以及相关页面信息,从而对相似用户群提供个性化服务。本文对Web站点的拓扑结构和用户浏览信息进行分析,以UserID为行、URL为列,构建UserID-URL关联矩阵,元素值为用户访问页面的次数。在此基础上,通过阈值参数的引入,将关联矩阵转化为加权关联矩阵,提出一种基于加权矩阵的聚类算法――多标记传播算法(multiMarker propagation algorithm)。该算法利用矩阵的稀疏特性,可从1个稀疏矩阵中抽出1个稠密子矩阵,因此,对用户(页面)聚类的过程,也转化为从稀疏矩阵中抽取稠密子矩阵的过程。
2 加权矩阵聚类
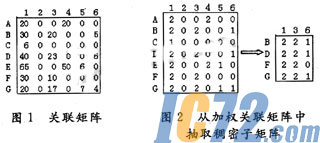
矩阵聚类(Matrix Cluster,MC)最初是为客户关系管理(Customer Relationship Management,CRM)提出的。图1所示的关联矩阵Mm×n中,行代表用户,列代表页面。矩阵元素值hi,j表示用户i访问页面j的次数。以往文献常见做法是用0或者1来表示用户是否访问某个页面,直接对关联矩阵进行归一化处理得到元素值非0即1的矩阵,再运用各种算法进行聚类分析。
为了更好地刻画用户的特征向量,反映出用户的访问频度和兴趣所在,本文引入加权关联矩阵的概念。加权关联矩阵Am×n由关联矩阵加权处理转化而来。通常这样的加权矩阵是个大而稀疏的矩阵。
进行加权处理的方法是,让关联矩阵的元素值和阈值∧比较:若hi,j=0,则ai,j=0,表示用户未访问;若hi,j≤∧,则ai,j=1,表示用户有一定兴趣;若hi,j>∧,则ai,j=2,表示用户很感兴趣。其中ai,j为加权关联矩阵Am×n的元素。阈值∧的计算方法采用关联矩阵所有元素的均值取整,即:
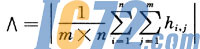
由于用户和页面的顺序不是很重要,所以行和列可以任意交换。图2显示了从给定加权矩阵中抽取出的稠密矩阵。如图所示,抽取出的稠密矩阵包括用户B,D,F,G及页面1,3,6,这个子矩阵可解释成如下这样:用户B,D,F,G在访问页面1,3,6时具有一个共同特征。同时页面1,3,6被用户B,D,F,G的访问也具有一个共同的特征。
下面给出支持度和置信度的概念:
支持度抽取出的子矩阵的面积,此处定义为:子矩阵的行×子矩阵的列;
置信度 抽取出的子矩阵的密度,即:子矩阵中非0元素的个数/子矩阵的面积;
这样,加权矩阵聚类的问题就转化为从稀疏矩阵中找出面积大于指定支持度且密度大于指定置信度的所有子矩阵的问题。
3 多标记传播算法
当矩阵很大时,一般算法会反复交换行或列,进行大量的计算,本文提出的基于加权矩阵聚类的多标记传播算法能够通过应用矩阵的稀疏特性来减少执行时间。该算法使用标记传播,标记传播通常定义为一个计算模型,它描述一个作为结点的处理单元和一个作为链接边的结点间的关系。标记传播通过从与结点N相连的活动结点传输一个标记的方式激活结点N。在多标记传播算法中,行(列)代表结点。当一个矩阵元素非O时,相应的行和列被一个双向边连接。当一个结点收到一个标记时,它会把该标记累积起来形成标记总数,标记总数通常用于裁剪。
如果某结点收到的标记总数小于指定的阈值,那么,该结点对应的行(列)被裁剪,被裁剪掉的行(列)不再参与后面的运算;需要说明的是,当执行行裁剪时,活动列只能激活那些与对应活动列标记相同的行。不过,由行发送标记时,只要对应列为非O元素均可被激活。标记会反复地在行(列)之间传播,直到活动的行(列)不再变化为止,即行(列)裁剪结束,此时如果发现剩余的活动行和列,均大于用户指定的行和列的最小值(支持度),并且矩阵密度也大于用户指定的最小密度(置信度),则剩余的活动行(列)对应的用户(页面)即为用户(页面)聚类,否则,说明没有满足要求的用户(页面)聚类存在。
为了算法的需要,这里引入几个概念:
用户信度:用户点击所有页面的累计次数;
页面信度:页面被所有用户点击的累计次数;
最小标记数:剪切矩阵的条件。
多标记传播算法结构如下:

由分析得知,多标记传播算法的时间复杂度为O((M+N)×M×N)。该算法会反复在行与列之间传播标记,直到活动的行与列不再变化为止,处理过程如图3所示。
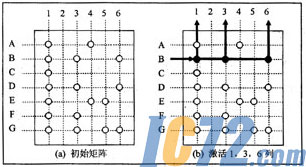
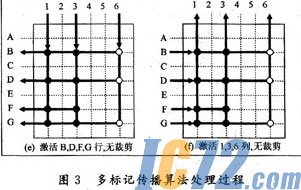
设最小支持度3×3=9,最小置信度0.8,最小用户信度1,最小页面信度1,最小标记阈值为2。
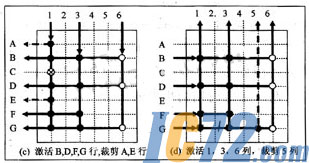
指定B行作为起始行,首先,B行最先处于激活状态,B行传送标记到与其相连的1,3,6列。下一步,活动列1,3,6分别传播相应的标记激活与其相连的行(A,B,D,E,F,G),列1将具有标记●的行B,D,E,F,G激活,由于C行标记不是●,故未被激活,用“?”表示,列3激活B,D,F行,列6以标记“○”激活B,D,G行,下面,执行行裁剪,先统计各行收到的标记总数,B,D,G行各收到的3个标记,F行收到两个标记,只有A,E行各收到一个标记,A,E行被裁剪掉,其他行(B,D,F,G)仍处于活动状态。按照上述的思路,继续传播标记,直到不执行行、列裁剪操作。此时得到满足最小置信度和最小支持度的子矩阵,即:B,D,F,G行和1,3,6列就构成了最后的聚类结果,处理过程结束。这里需要指出,选择不同的起始行,则会得到不同的聚类结果。若以A行作为初始行,则得到的聚类结果为由A,E,G行和1,4,5列组成的子矩阵。
聚类过程每一步得到的包含活动行列的子矩阵面积和密度都很容易计算。例如,最终结果的子矩阵面积为3×4=12,大于最小支持度9;密度可以根据活动状态上收到的标记结点总数除以面积计算,矩阵密度为1l/12=0.92,满足最小密度0.8的条件。
多标记传播算法依照给定的输入进行计算,其中最重要的环节是裁剪策略。裁剪是通过收到的标记总数与最小阈值进行比较,因此,选择合适的阈值对最后的聚类结果影响很大。如果上述例子中的最小阈值设置为3,只能得到B,D,G行;如果设置为4,则得不到任何的聚类。不同的输入条件也会影响到聚类结果。如果在上述例子中将置信度设为0.95,将不会得到满足条件的任何聚类。若上述例子中将最小用户信度设置为2,则行C在算法开始就会被裁剪,不会参加循环聚类,大大提高了聚类的计算量,如果置信度为3,将直接得到B,D,G行,虽然比较快速,但裁剪了F行,使得聚类的结果不太精确。
4 应用实例及实验结果
Web访问日志是Web服务器用以记录用户访问网站各页面情况的文件。对Web日志进行数据采集、预处理后,得到每个用户访问每个URL页面的信息。用本文提出的多标记传播算法实现用户聚类,把用户划分成若干个用户群,具有相似访问模式的用户被分在同一个群体中,相同用户群中所访问的页面也具有相同的特征。
为了验证多标记传播算法的有效性,实验提取某高校网站Web服务器上1天的日志记录,共57138条记录,数据净化后得到5126条记录,经过数据清洗、用户识别和格式化操作后提取112个用户和53个URL页面数,使用本文提出的算法最后识别出6类用户群,图4以柱形图的形式直观地表示最终的用户聚类情况。

5 结 语
本文描述加权矩阵聚类及其在Web日志挖掘中的应用,通过构建UserID-URL关联矩阵,引入加权关联矩阵的概念,提出一种基于加权矩阵的聚类算法――多标记传播算法,该算法利用矩阵的稀疏特性,从一个稀疏矩阵中抽出一个稠密子矩阵实现用户(页面)聚类,实验表明,该算法用于Web日志挖掘中高效可靠。
|