引 言
在32位微处理器逐渐成为嵌入式系统主流的同时,嵌入式应用也变得越来越复杂。许多嵌入式系统都不得不借助于专用的操作系统来支撑自己的应用。uClinux作为类Unix操作系统,继承了Linux的各种优秀的品质,成为首选的嵌入式系统的操作系统。
为自己的设备在操作系统下添加驱动程序,是嵌入式设计必不可少的部分。针对不同的设备类型,选择合适的驱动程序的模式,同样也是十分重要的。通常的设备驱动采用直接I/O的方式,如存储器、看门狗等;而对于象网络这样的数据流设备的驱动,则应该用到中断机制。
本文以uClinux为背景,以一种数据流设备为目标,介绍中断驱动的I/O设备驱动的开发。
1 应用背景
1.1 硬件描述
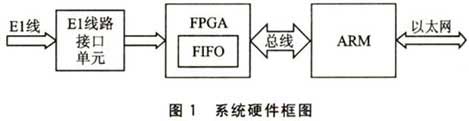
本文介绍的驱动程序是应用在一种电信E1线路和以太网互联设备上的。它是旁路接收E1数据并将其发送到以太网的某一台服务器上,在服务器上对E1的话路和信令时隙分析。
该设备中的处理器是采用三星公司出品的网络型ARM处理器S3C4510B。E1线路接口采用Dallas半导体公司的专用El接口单元(LIU)芯片DS2148,它完成波形整理、时钟恢复和HDB3解码。DS2148将整理后的E1数据流送给一片Altera公司的Cyclone系列的FPGA(EPlC3T144C8),它将串行的E1数据流存入到FIFO,再通过ARM的32位外部总线将数据传送给ARM。ARM将数据打包通过以太网发送到服务器上。图l所示是本系统的硬件框图。本文主要介绍接在ARM的外部总线上的FPGA,在uClinux下的驱动程序中断机制的设计。
1.2硬件连接
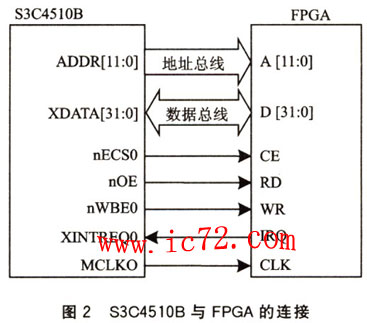
S3C4510B处理器和FPGA的连接电路如图2所示。
1.3 FPGA内FIFO的结构
在FPGA内部设置了两个FIFO。为了防止ARM和FPGA操作的冲突,ARM和FPGA对两个FIFO操作采用乒乓方式,这样ARM和FPGA就可以同时操作不同的FIFO,而不需要等待。FIFO的大小是4096位,能容纳一个E1复帧的数据量。当FPGA将一个FIFO填满后,会用中断的方式通知ARM来读FIFO,同时FPGA会置内部的F1FO状态寄存器。FIFO)状态寄存器命名为fpga_imf,是一个32位的寄存器,用其中某几位置“l”,表示对应的FIFO需要读取。
2 软件设计
中断驱动的I/O是指,输人数据在中断期间被填充到缓冲区内,并由读取该设备的进程取走缓冲区内的数据;输出缓冲区由写设备的进程填充,并在中断期间取走数据。数据缓冲可以将数据的发送和接收与write及read系统调用分离开来,提高系统的整体性能。下面是uCllnux下的中断程序的设计。
2.1 uClinux下的中断程序
在uClinux系统中,通过调用下面这个函数向系统申请一个中断通道(或中断请求IRQ),并在处理完以后释放掉它。
mt reqLIest_irq(unsigned int irq,void(*handler)(int,vold*,
struct pt_regs*),unsigned 10ng flags,const chat*device,
vold*dev_id);
void free_irq(unstgned int lrq,VOid*dev_id);
其中,irq是中断号。在本系统中它对应于S3C4510B的21个中断源。这里用的是中断源O。handler指向要安装的中断处理函数的指针。flags是一个与中断管理有关的各种选项的字节掩码。device传递给request_irq的字符串,在/proc/interrupts中用于显示中断的拥有者。dev_id指针用于共享的中断信号线。函数的返回值为O时表示成功,或者返回一个负的错误码。函数返回一EBUJSY通知另一个设备驱动程序已经使用了要申请的中断信号线。下面是FPGA的设备中断申请函数。这个函数是在驱动中的fpga_open函数中被调用的。
int fpga_open(struct inode*inocle,stuct_file*file){
int result;
result=request_irq(FPGA_IRQ,δfpga_isr,SA_INTER-RUPT,″fpga″,NULL);
if(resuIt!=O){
printk(KERN_INFO”Can not register FPGA ISR!\n”);}else{
printk(KERN_INFO″FPGA ISR Register successfully!\n”);
}
}
在申请了中断通道后,系统会响应外部中断0,而进入中断处理程序。中断处理程序的第一步是要先清除S3C4510B的中断悬挂寄存器的外部中断O位。这是为了让FPGA可以产生新的中断。在uClinux系统中是调用下面的宏来实现的。
#deflne CLEAR_PEND_INT(n) IntPend=(1<<(n))
中断处理程序功能就是将有关中断接收的信息反馈给设备,并根据要服务的中断的不同含义相应地对数据进行读写。所以FPGA的中断处理的主要任务是,读取FPGA中FIFO状态寄存器的值,获取需要读取的FIFO的信息并安排接收数据。在程序中用到了系统提供的inl函数。
unmgned mt status
status=inl(FPGA_IMF);
中断处理程序的执行应尽可能的短,而从FPGA中接收数据,一次必须读完一个FIFO及128字。这是一个需要较长时间的外部I/O操作,所以把这个操作放到中断处理的底半部(bottom-haIf)来完成。下面介绍中断处理的底半部的设计。
2.2 BH机制
底半部处理程序和上半部最大的不同就在于,在执行BH时所有的中断都是打开的,所以说它是在“更安全”时间内运行。2.4版本的uClinux内核有三种机制来实现底半部的处理:软中断、tasklet和BH。在这里选用了较为简单的BH机制。
BH机制实际上是一个任务队列,中断处理程序将要处理的任务插到特定的任务队列中等待内核执行。内核维护着多个任务队列,但驱动程序只能用前三种:
①tq_scheduler队列。当调度器被运行时,该队列就会被处理。因为此时调度器在被调度出的进程的上下文中运行,所以该队列中的任务几乎可以做任何事。它们不会在中断时运行。
②tq_timer队列。该队列由定时器队列处理程序(timertick)运行,因为该处理程序是在中断时问运行的。该队列中的所有任务就也是在中断时间内运行的。
③tu_lmmediate队列。立即队列在系统调用返回时或调度器运行时尽快得到处理的(不管两种情况谁先发生了)。该队列是在中断时间内得到处理的。
队列元素由下面的结构来描述:
structtq_struct
structq_struct*mext /*激活的BH的链接表*/
unsigned 1ong sync; /*必须初始化为零*/
void(*outine)(vold*); /*调用的函数*/
void*data; /*传递给函数的参数*/
};
上面的数据结构中最重要的字段是rotltine和data。将要延迟的任务插入队列,必须先设置好结构的这些字段,并把next和sync两个字段清零。结构中的sync标志位用于避免同一任务被插人多次,这会破坏next指针。一旦任务被排人队列,该数据结构就被认为是内核“拥有”了,不能再被修改。
在FPGA的驱动中,定义了一个任务队列元素用于完成底半部分:
struct tq_struct el_task;
unsigned int el_line;
el_line数组用来保存传递给任务的参数。在打开FPGA时要对任务队列结构赋值:
el_task.routine=fpga_bh;
e1 task.data=&e1_line:
上面的fpga_bh是底半部分处理函数void fpga_bh(unsigned int*line)的函数名,el_line是传递给fpga_bh函数的实参。
与任务队列有关的还有下面的函数:
void queue_task(struct tq_struet*task,task_queue*List);
正如该函数的名字,本函数用于将任务排进队列中。它关闭了中断,避免了竞争,因此可以被模块中任一函数调用。FPGA的任务被插入到tq_immediate队列中,所以,list被赋值为&tq_immediate。
当某段代码需要调度运行下半部处理时,只要调用mark_bh即可:
void mark_bh(int nr);
这里,nr是激活的BH的类型。这个数是在头文件中定义的一个符号常数。每个下半部BH相应的处理函数由拥有它的那个驱动程序提供。
完成任务队列元素设置后,中断处理函数中就可以启用BH机制。在读得fpga_imf的值后将其赋给el_line,然后调用queue_task将任务插入到tq_immediate队列中,再调用mark_bh(IMMEDIATE_BH),启动底半部分处理。到此,中断处理程序就可以退出了。
2.3底半部分处理程序和缓冲区
uClinux操作系统退出中断处理程序后,会立即将tq_immediate队列中任务投入运行,其中也有fpga_bh函数。在进入fpga_bh同时,系统会将el_line的地址作为实参传递给形参line。也就是将FIFO状态寄存器(fpga_imf)的值间接传给了底半部处理程序。底半部分程序中会检查这个值的每一位,据此决定需要读的FIFO。
从FIFO中读上来的数据都是存放在内核的缓冲区中的。因为每一个FIFO的容量是一个E1的复帧,所以内核的缓冲也是以E1复帧的大小为一个缓冲块。缓冲块用链表串连起来。缓冲单元的数据结构如下:
struct buf_struct{
struct list_head list; /*链表头*/
unsigned int buf_size; /*数据块的大小*/
unsigned int*buLhead; /*缓冲块的指针*/
unsigned int*buL_curl /*缓冲块当前指针*/
};
buf_size说明了数据块的大小。这是一个以“字”为单位的数值。缓冲块在内核堆区开辟,buf_head指向实际的缓冲块的首地址,而buf_cur指向缓冲块中正在操作的单元。为了使用链表机制,驱动必须包含头文件。其中定义了list_head类型结构:
struct list_head{
struct list_head*next.*prev;
为了访问缓冲块链表,还要建立一个链表头,在驱动 中定义全局变量:
struct list_head read_list;
链表头必须是一个独立的list_head结构。在使用之前,必须用INIT_LIST_HEAD宏来初始化链表头:
INIT_LIST_HEAD(&readlist); I
Linux系统提供了链表的操作函数,在头文件中:
list_add(struet list_head*new,struct list_head*head); /*在链表头后插入一个新项*/
list_add_tail(stuot list_head*new,struet list_head*head); /*在链表尾部添加一个新项*/
list_del(struet_list_head*entry); /*将给定项从链表中删除*/
list_empty(struct list_head*head) /*判断链表是否为空*/
list_entry(struct list_head。ptr,type_of_struet,field_ name); /*访问包含链表头的结构*/
其中list_entry的作用是一个1ist_head结构指针映射回一个指向包含它的大结构的指针。ptr是指向structlist_head结构的指针,type_of_struct是包含ptr的结构类型,field_name是结构中链表字段的名字。如可以用这个宏将指向数据缓冲块的链表指针(readl)映射为缓冲块结构指针(buf):
struet buf_strcut*buf=list_entry(real,struct buf_struct,list);
底半部分处理程序中,内核缓冲块是动态分配的。因为驱动程序是内核的一部分,所以在内核堆区开辟缓冲区就要用专用的函数,在头文件定义了如下函数:
void*kmalloc(size t size,int flags);/*在内核堆中分配size大小的空问*/
void kfree(void*obi/*释放kmalloc分配的空间*/
kmalloc函数的第1个参数是size(大小),第2个参数是优先权。最常用的优先权是GFP_KERNEL,它的意思是该内存分配是由运行在内核态的进程调用的。有时kmalloc是在进程上下文之外调用的,比如在中断处理、任务队列处理和内核定时器处理时发生。这些情况下,current进程就不应该进入睡眠状态,这时应该就使用优先权GFP_ATOMIC。
不要过于频繁地用kmalloc在内核堆中分配空间,因为在分配空间时可能有中断到来,这样是不安全的。在驱动中建立另一个链表用于回收使用过的缓冲块。在驱动中用free_1ist作为回收缓冲块的链表头:
struct list_head free_list;
这样就存在两个链表:一个是装载着数据的链表,一个是已经使用过的缓冲块的链表(称为自由链表)。那么只要自由链表中还有表项,在需要缓冲块时就可以直接从自由链表中取出一个使用,而不用kmalloc再去分配。
2.4 阻塞型I/O和自旋锁的使用
在驱动程序中,read的工作是将内核缓冲区中拷贝到用户空间。在进行这种操作时有两种情况是应该注意的:
①当read时发现读链表是空,也就是还没有数据可读。
这种情况下,可以让read立即返回一EAGAIN,告知用户进程没有读到数据;另一个办法就是实现阻塞型I/O,在没有数据可读时让用户进程进入睡眠状态并等待数据。
有几种处理和唤醒的方法,都要处理同一个基本的数据类型――等待队列(walt_queue_head_t),就是由正在等待某事件发生的进程组成的一个队列。使用之前必须声明和初始化,在驱动程序中是如下声明的:
wait_queue_head_t read_Jqueue;
init_waitqueue_head(&read_queue);
可以调用如下函数之一让进程进入睡眠状态:
void wait_evet(wait_queue_head_ queue,int condition);
int wait_evem_interruptible(Walt_queue_hean_t queue,int condition);
这两个函数把等待事件和测试事件是否发生合并起来。调用之后,进程会一直睡眠到C布尔表达式condition为真时为止。在驱动中的read函数中,判断读链表为空,就调用它进入睡眠:
while(1ist_efnpty(&read_list)){
If(filp一>f_flags δO_NoNBLOCK)/*如果设置成非阻塞I/o*/
return―EAGAIN;
if(wait_evert_interruptible(read_queue,!list_empty(δread_list))) return―ERESTARTSYS;
}
对应上面的函数,要唤醒进程可以调用下面的函数:
wake_up(wait_queue_gead_t*queue);
wake_up_jnterruptlbk(wait_queue_head_t*queue);
驱动程序应该在数据到来后及时唤醒进程,也就是从FIFO读取数据后,在退出底半部处理程序前执行:
wake_up_mterIuptible(&read_queue);
要指出的是被唤醒并不保证等待的事件发生了,所以从睡眠态返回后,应该循环测试condition。
②当read操作正在访问某一个链表时,底半程序也要访问同一个链表。这样是比较危险的,应该避免。
为了避免这种情况的发生,这里使用自旋锁。在read操作访问链表前获得锁,访问结束时解锁。底半部要访问链表时先要检查自旋锁是否已上锁,如果有,则等待到锁可用。
自旋锁使用类型spinlock_t来描述。自旋锁被声明和初始化为不加锁状态方式如下:
spinlock_t1ist_10ck=SPIN_LoCK_UNLOCKED;
处理自旋锁的函数如下:
spill_1ock_bh(Spllalock-t*1ock);
spin_unloek_bh(splnlock_t*lock);
这里使用获得自旋锁并且阻止底半部执行的函数,就可以完全保证底半部程序不会在read操作访问链表时来访问链表。程序中如下实现:
spln_lock_bh(&list_lock);
list_del(readl); /*将使用后的缓冲块从读链表中删除*/
list_add_tail(readI,&free_list);/*将使用后的缓冲块插入自由链表中*/
spin_unlock_bh(&list_lock);
2.5中断驱动的I/O
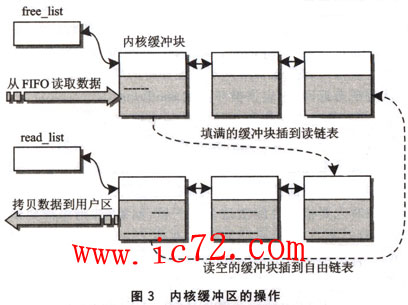
至此,可以完整地描述ARM与FPGA之间数据流动的过程:当FPGA的一个FIFO满后,向ARM发出中断,ARM进入中断处理程序后,读取FPGA中的FlFO状态寄存器(fpga_imf)的值,然后把一个任务插到立即队列(tq_imrnediate)中,启动底半部分(BH),同时将FIFO)状态寄存器的值传递给底半部分处理程序(fpga_bh),完成这些工作后退出中断处理程序。进入底半部分处理程序后,根据FIFO状态寄存器的值确定要处理的F1F0。从FIFO中将数据读出存人到内核缓冲块中,这个缓冲块可能是从自由队列(free_list)中取出来的一个。如果自由队列中是空的,就新分配一个缓冲块。接下来将填好的缓冲块加到读队列(read-list)中,并唤醒睡眠的进程,这样底半部分的工作也完成了。当用户进程对FPGA设备进行读操作时,驱动中的read函数检查读链表。如果读链表为空,则进入睡眠并等待数据到来。有数据后将从读队列中取出的缓冲块的数据拷贝到用户空间,然后将使用过的缓冲块插到自由队列中,等待以后再次使用。内核缓冲区的操作过程如图3所示。图3上半部分是在底半部分程序中,下半部分是在read函数中。
结 语
连续数据流设备在uClinux下的驱动,通常会用到中断机制。本文讨论的中断驱动的I/O式为这种应用提供了一种实用的方法。文中所涉及的链表、阻塞型I/O、自旋锁等技术在驱动程序的开发中也经常得到使用。 |