存储器技术的发展使存储器系统的性能得到提高,尽管峰值速率依然是存储器技术最重要的参数之一,但其它结构参数也极大地影响存储器系统的性能。本文将重点介绍存储器架构对系统性能的影响。
存储器技术大多数根据其运行速度来命名。例如,PC100 SDRAM器件是指数据速率为100MHZ的存储技术,PC133则表示数据速率为133MHz,等等。尽管这种命名的习惯随着时间发展而变化,但通常还是能给潜在买家提供关于存储器运行速度的信息。事实上,今天的主流存储技术都是按照其峰值数据速率来命名的,这将继续成为评估存储系统性能的要素之一。不过,在实际系统中,没有存储器能完全工作在其峰值速率下。
从写命令转换到读命令,在某个时间访问某个地址,以及刷新数据等操作都要求数据总线在一定时间内保持休止状态,这样就不能充分利用存储器通道。此外,宽并行总线和DRAM内核预取都经常导致不必要的大数据量存取。在指定的时间段内,存储器控制器能存取的有用数据称为有效数据速率,这很大程度上取决于系统的特定应用。有效数据速率随着时间而变化,常低于峰值数据速率。在某些系统中,有效数据速率可下降到峰值速率的10%以下。
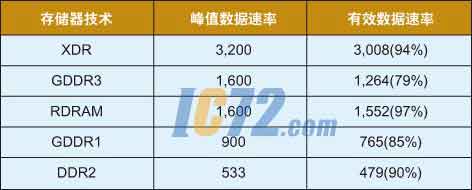
表1:每百周期发生两个总线转换时的有效数据速率和峰值数据速率。
通常,这些系统受益于那些能产生更高有效数据速率的存储器技术的变化。在CPU方面存在类似的现象,最近几年诸如AMD和 Transmeta等公司已经指出,在测量基于CPU的系统的性能时,时钟频率不是唯一的要素。存储器技术已经很成熟,峰值速率和有效数据速率或许并不比以前匹配的更好。尽管峰值速率依然是存储器技术最重要的参数之一,但其他结构参数也可以极大地影响存储器系统的性能。
影响有效数据速率的参数
有几类影响有效数据速率的参数,其一是导致数据总线进入若干周期的停止状态。在这类参数中,总线转换、行周期时间、CAS延时以及RAS到CAS的延时(tRCD)引发系统结构中的大部分延迟问题。
总线转换本身会在数据通道上产生非常长的停止时间。以GDDR3系统为例,该系统对存储器的开放页不断写入数据。在这期间,存储器系统的有效数据速率与其峰值速率相当。不过,假设100个时钟周期中,存储器控制器从读转换到写。由于这个转换需要6个时钟周期,有效的数据速率下降到峰值速率的 94%。在这100个时钟周期中,如果存储器控制器将总线从写转换到读的话,将会丢失更多的时钟周期。这种存储器技术在从写转换到读时需要15个空闲周期,这会将有效数据速率进一步降低到峰值速率的79%。表1显示出针几种高性能存储器技术类似的计算结果。
显然,所有的存储器技术并不相同。需要很多总线转换的系统设计师可以选用诸如XDR、RDRAM或者DDR2这些更高效的技术来提升性能。另一方面,如果系统能将处理事务分组成非常长的读写序列,那么总线转换对有效带宽的影响最小。不过,其他的增加延迟现象,例如库(bank)冲突会降低有效带宽,对性能产生负面影响。
DRAM技术要求库的页或行在存取之前开放。一旦开放,在一个最小周期时间,即行周期时间(tRC)结束之前,同一个库中的不同页不能开放。对存储器开放库的不同页存取被称为分页遗漏,这会导致与任何tRC间隔未满足部分相关的延迟。对于还没有开放足够周期以满足tRC间隙的库而言,分页遗漏被称为库冲突。而tRC决定了库冲突延迟时间的长短,在给定的DRAM上可用的库数量直接影响库冲突产生的频率。
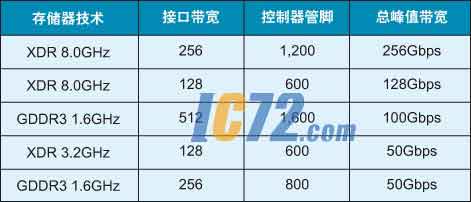
表2:不同存储技术的总峰值带宽以及控制器管脚数的总线带宽。
大多数存储器技术有4个或者8个库,在数十个时钟周期具有tRC值。在随机负载情况下,那些具有8个库的内核比具有4个库的内核所发生的库冲突更少。尽管tRC与库数量之间的相互影响很复杂,但是其累计影响可用多种方法量化。
存储器读事务处理
考虑三种简单的存储器读事务处理情况。第一种情况,存储器控制器发出每个事务处理,该事务处理与前一个事务处理产生一个库冲突。控制器必须在打开一个页和打开后续页之间等待一个tRC时间,这样增加了与页循环相关的最大延迟时间。在这种情况下的有效数据速率很大程度上决定于I/O,并主要受限于DRAM内核电路。最大的库冲突频率将有效带宽削减到当前最高端存储器技术峰值的20%到30%。
在第二种情况下,每个事务处理都以随机产生的地址为目标。此时,产生库冲突的机会取决于很多因素,包括tRC和存储器内核中库数量之间的相互作用。tRC值越小,开放页循环地越快,导致库冲突的损失越小。此外,存储器技术具有的库越多,随机地址存取库冲突的机率就越小。
第三种情况,每个事务处理就是一次页命中,在开放页中寻址不同的列地址。控制器不必访问关闭页,允许完全利用总线,这样就得到一种理想的情况,即有效数据速率等于峰值速率。
第一种和第三种情况都涉及到简单的计算,随机情况受其他的特性影响,这些特性没有包括在DRAM或者存储器接口中。存储器控制器仲裁和排队会极大地改善库冲突频率,因为更有可能出现不产生冲突的事务处理,而不是那些导致库冲突的事务处理。
然而,增加存储器队列深度未必增加不同存储器技术之间的相对有效数据速率。例如,即使增加存储器控制队列深度,XDR的有效数据速率也比 GDDR3高20%。存在这种增量主要是因为XDR具有更高的库数量以及更低的tRC值。一般而言,更短的tRC间隔、更多的库数量以及更大的控制器队列能产生更高的有效带宽。
实际上,很多效率限制现象是与行存取粒度相关的问题。tRC约束本质上要求存储器控制器从新开放的行中存取一定量的数据,以确保数据管线保持充满。事实上,为保持数据总线无中断地运行,在开放一个行之后,只须读取很少量的数据,即使不需要额外的数据。
另外一种减少存储器系统有效带宽的主要特性被归类到列存取粒度范畴,它规定了每次读写操作必须传输的数据量。与之相反,行存取粒度规定每个行激活(一般指每个RAS的CAS操作)需要多少单独的读写操作。列存取粒度对有效数据速率具有不易于量化的巨大影响。因为它规定一个读或写操作中需要传输的最小数据量,列存取粒度给那些一次只需要很少数据量的系统带来了问题。例如,一个需要来自两列各8字节的16字节存取粒度系统,必须读取总共32字节以存取两个位置。因为只需要32个字节中的16个字节,系统的有效数据速率降低到峰值速率的50%。总线带宽和脉冲时间长度这两个结构参数规定了存储器系统的存取粒度。
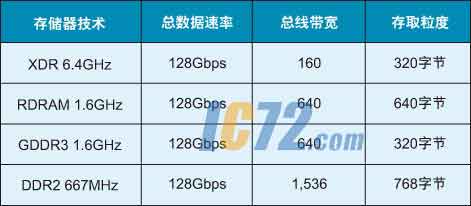
表3:目前主流存储技术的存取粒度和总线带宽值。
总线带宽是指连接存储器控制器和存储器件之间的数据线数量。它设定最小的存取粒度,因为对于一个指定的存储器事务处理,每条数据线必须至少传递一个数据位。而脉冲时间长度则规定对于指定的事务处理,每条数据线必须传递的位数量。每个事务处理中的每条数据线只传一个数据位的存储技术,其脉冲时间长度为1。总的列存取粒度很简单:列存取粒度=总线宽度×脉冲时间长度。
很多系统架构仅仅通过增加DRAM器件和存储总线带宽就能增加存储系统的可用带宽。毕竟,如果4个400MHZ数据速率的连接可实现 1.6GHz的总峰值带宽,那么8个连接将得到3.2GHz。增加一个DRAM器件,电路板上的连线以及ASIC的管脚就会增多,总峰值带宽相应地倍增。
首要的是,架构师希望完全利用峰值带宽,这已经达到他们通过物理设计存储器总线所能达到的最大值。具有256位甚或512位存储总线的图形控制器已并不鲜见,这种控制器需要1,000个,甚至更多的管脚。封装设计师、ASIC底层规划工程师以及电路板设计工程师不能找到采用便宜的、商业上可行的方法来对这么多信号进行布线的硅片区域。仅仅增加总线宽度来获得更高的峰值数据速率,会导致因为列存取粒度限制而降低有效带宽。
假设某个特定存储技术的脉冲时间长度等于1,对于一个存储器处理,512位宽系统的存取粒度为512位(或者64字节)。如果控制器只需要一小段数据,那么剩下的数据就被浪费掉,这就降低了系统的有效数据速率。例如,只需要存储系统32字节数据的控制器将浪费剩余的32字节,进而导致有效的数据速率等于50%的峰值速率。这些计算都假定脉冲时间长度为1。随着存储器接口数据速率增加的趋势,大多数新技术的最低脉冲时间长度都大于1。
内核预取
一种称为内核预取的功能主要负责增加最小的脉冲时间长度。DRAM内核电路不能跟上I/O电路速度的速增。由于数据不能再连续地从内核中取出以确保控制器需求,内核通常为I/O提供比DRAM总线宽度更大的数据集。
本质上,内核传输足够的数据到接口电路,或者从接口电路传输足够的数据,以使接口电路保持足够长时间的繁忙状态,以便让内核准备下一个操作。例如,假设DRAM内核每个纳秒才能对操作响应一次。不过,接口可以支持每纳秒两位的数据速率。
DRAM内核每次操作取两个数据位,而不是一个数据位,因而不必浪费接口一半的容量。在接口传输数据之后,内核已经准备好响应下一个请求,而不需增加延时。增加的内核预取导致最小脉冲时间长度增加为2,这将直接影响列存取粒度。
对于每个增加到总线宽度的额外信号,存储器接口将传输两个额外的数据位。因此具有最小脉冲时间长度为2的512位宽的存储系统,其取粒度为 1,024位(128字节)。很多系统对最小存取粒度的问题并不敏感,因为它们存储大量的数据。不过,某些系统依赖存储器系统提供小的数据单元,并获益于更窄、更有效的存储器技术。
本文小结
随着存储技术向峰值数据速率发展,有效的数据速率变的越来越重要。在选择存储器时,设计师必须深入了解已公布的存储器规范,并明白某个特定的技术特性将对应用设计产生怎样的影响。存储器系统设计师必须超越峰值数据速率规范,就像CPU设计师不再用千兆Hz作为唯一的性能衡量标准一样。尽管对于存储器接口而言,峰值数据速率依然是最终要的性能规范,但有效的数据速率已开始为系统设计师和架构师提供更大的空间。未来产品的性能将极大地取决于其存储器系统的有效利用程度。 |