ХЄ ТЄЈєНЁУГјЖЛг»ъПµНіУЙУЪЖдјЫёсµНБ®ЎўёЯФЛЛ㹦ДЬµИМШµгЈ¬ТСѕ±»№г·єУ¦УГУЪ№¤ТµЙъІъЎўЖыіµїШЦЖЎўєЅМмµјєЅµИКµК±БмУтЎЈµ«КЗЈ¬НЁУГјЖЛг»ъПµНіµДЙијЖДїµДКЗОЄБЛИЎµГёьёЯµДЖЅѕщ№¦ВКЈ»Ж䴦АнЖчЅб№№єНУІјюјУЛЩ»ъЦЖ»б¶ФПµНіµДКµК±МШРФФміЙТ»¶ЁµДУ°ПмЎЈ±ѕОД·ЦОцБЛРВРНNUMA(·ЗѕщФИґжґўЖч·ГОК)Ѕб№№¶аґ¦АнЖчПµНіµДЕдЦГЗйїцЈ¬ФЪґЛ»щґЎЙПМЦВЫБЛNUMAЅб№№¶ФУЪПµНіКµК±МШРФµДУ°ПмЈ¬ёшіцБЛКµК±РФДЬµДІвКФ·Ѕ°ёєНІвКФЅб№ыЎЈ
№ШјьґКЈєКµК±РФДЬЈ»¶аґ¦АнЖчПµНіЈ»HyperTransportЈ»NUMAЈ»TSCЈ»ЅЪµг
ТэСФ
---ЅьДкАґЈ¬јЖЛг»ъјјКхІ»¶П·ўХ№Ј¬ґ¦АнЖчµДРФДЬТІІ»¶ПМбёЯЈ¬µ«КЗРФјЫ±ИИґІоЗїИЛТвЈ¬ИзXeonґ¦АнЖчЈ¬К±ЦУЖµВКГїМбёЯ7ЈҐЈ¬ПаУ¦µДјЫёсѕНТЄЙПХЗ40ЈҐЎЈТтґЛРн¶аЖуТµІЙУöദАнЖчµД·ЅКЅАґМбёЯПµНіРФДЬЈ¬ЧчОЄ·юОсЖчАґЦ§іЦ¶аИООс¶аПЯіМІўРРµД№¤ЧчРиТЄ,іцПЦБЛИзSMP(¶ФіЖ¶аґ¦Ан)ЎўMPP(ґу№жДЈІўРРґ¦Ан)єНNUMAµИ¶аЦֶദАнЖчЅб№№Ј¬ЖдЦРNUMAЅб№№ТФЖдДЈїйїЙА©Х№»ЇХэµГµЅФЅАґФЅ№г·єµДУ¦УГЎЈИзєОЅ«¶аґ¦АнЖчПµНіУ¦УГУЪКµК±ПµНіЦРЈ¬ХэіЙОЄДїЗ°СРѕїµДИИГЕЎЈ±ѕВЫОД»щУЪ±КХЯФЪµВ№ъДЅДбєЪ№¤ТµґуС§КµК±ПµНіСРѕїЦРРДЛщґУКВµДµВ№ъ№ъјТСРѕїЦРРДRECOMSПоДїЈ¬ПµНіµШ·ЦОцБЛNUMAЅб№№µДЕдЦГЗйїцЈ¬ТФј°Жд¶ФХыёцПµНіКµК±МШРФµДУ°ПмЈ¬ІўёшіцБЛПаУ¦µДІвКФ·Ѕ°ёєНІвКФЅб№ыЈ¬ЅшТ»ІЅЦ¤ГчБЛNUMAЅб№№УГУЪКµК±ПµНіµДїЙРРРФЈ¬їЄґґБЛКµК±ПµНіСРѕїµДРВ·Ѕ·ЁЎЈ
1 NUMAЅб№№ПµНіј°ЖдЕдЦГ
1.1 HyperTransport јјКх
---ЛжЧЕґ¦АнЖчЎўґжґўЖчЎўНјРОјјКхµИІ»¶П·ўХ№Ј¬ПµНіДЪІїґуКэѕЭБчµДґ«КдіЙОЄТ»ЦЦ±ШИ»ЗчКЖЎЈґ¦АнЖчµДРФДЬГї18ёцФВѕНДЬМбёЯТ»±¶Ј¬¶шI/OЧЬПЯјјКхµДРФДЬГї3ДкІЕДЬМбёЯТ»±¶Ј¬УЙґЛґшАґµДI/OЖїѕ±ОКМвґуґуПЮЦЖБЛПµНіХыМеРФДЬµДМбёЯЎЈјшУЪґЛЦЦЗйїцЈ¬AMDєНAPI Networks№«ЛѕєПЧчїЄ·ўБЛHyperTransportЧЬПЯБ¬ЅУјјКхАґґъМжґ«НіµДPCIЎўPCI-XµИЧЬПЯДЈКЅЈ¬МбёЯЧЬПЯµДґшїнТФґпµЅМбёЯПµНіХыМеРФДЬµДДїµДЎЈ
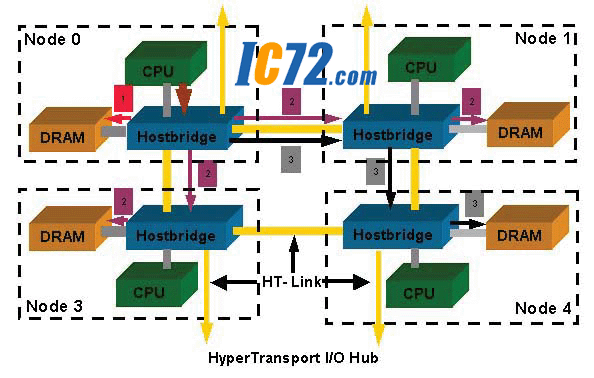
---HyperTransportјјКхУЙКэѕЭВ·ѕ¶ЎўїШЦЖРЕєЕТФј°К±ЦУРЕєЕЧйіЙµг¶ФµгµҐПтБґВ·Ј¬ГїТ»МхКэѕЭВ·ѕ¶¶јїЙТФСЎФс2Ўў4Ўў8Ўў16»тХЯ32О»µДґшїнЈ»ГьБоЎўµШЦ·єНКэѕЭ№ІУГКэѕЭВ·ѕ¶Ј¬Н¬К±УЙКэѕЭВ·ѕ¶ЎўїШЦЖРЕєЕєНК±ЦУРЕєЕЧйіЙБґВ·ЎЈHyperTransportІЙУГµДКЗІо¶ЇКЅµДКэѕЭґ«Кд·ЅКЅЈ¬јґГїТ»О»¶јКЗУЙБЅМхґ«КдПЯЦ®јдµДС№ІоАґИ·¶ЁЖдЦµЈ¬µ±AПЯµзС№ёЯУЪBПЯК±ОЄЎ°1Ў±Ј¬·ґЦ®ОЄЎ°0Ў±ЎЈ HyperTransportЧЬПЯµДФЛРРµзС№ЅцОЄ1.2VЈ¬ВъЧгБЛёЯЛЩКэѕЭґ«Кд¶ФµН№¤ЧчµзС№µДТЄЗуЎЈТтґЛЈ¬Па¶ФУЪЖдЛыI/OјјКхЈ¬HyperTransportјјКхј«ґуµШМбёЯБЛЧЬПЯµДґшїнЈ¬ґ«НіµДPCIЧЬПЯµДґ«КдЛЩВКОЄ133M/s, А©Х№µДPCI-XµДґшїнОЄ1G/s,IntelµДInfiniBandЧоёЯґшїнОЄ4G/sЈ»¶шHyperTransportЧЬПЯµҐПтґ«КдЛЩВКОЄ6.4G/s,КЗґ«НіPCIµД50±¶ЎЈТтґЛЈ¬HyperTransportЧЬПЯјјКх±»№г·єУ¦УГУڶദАнЖчПµНіµИґуКэѕЭБїґ«КдПµНіТФЧоґуПЮ¶ИµШМбёЯґшїнєНЛх¶МПмУ¦К±јдЈ¬ИзNUMAЅб№№¶аґ¦АнЖчПµНіЈ¬HyperTransportјјКхµДУ¦УГ·ЅКЅИзНј1ЛщКѕЎЈ
1.2 NUMAЅб№№¶аґ¦АнЖчПµНіµДКµПЦєНЕдЦГ
1.2.1 NUMAПµНіµД»щ±ѕЅб№№
---ґ«НіµДґ¦АнЖчПµНіІЙУГДП±±ЗЕ»ъЦЖКµПЦґ¦АнЖчєНДЪґжТФј°НвЙиЦ®јдµДКэѕЭґ«КдЎЈЖдЦРЈ¬ДПЗЕЦчТЄёєФрI/OЅУїЪТФј°IDEЙи±ёµДїШЦЖЈ¬ДПЗЕНЁ№эЧЬПЯєН±±ЗЕБ¬ЅУЈ»±±ЗЕКЗЦч°еЙПАлCPUЧоЅьµДТ»їйРѕЖ¬Ј¬ёєФрCPUУлPCIЙи±ёЎўCacheТФј°ДЪґжїШЦЖЖчЦ®јдµДБ¬ЅУЎЈNUMAЅб№№ЦРІЙУГHyperTransportµДHostbridgeєНI/O Hub·Ц±рґъМжБЛґ«НіµД±±ЗЕєНДПЗЕЈ¬КµПЦБЛєНДП±±ЗЕПаН¬µД№¦ДЬЈ¬µ«КЗИґґуґуМбёЯБЛКэѕЭґ«КдЛЩВКЎЈНј1ЦРПФКѕБЛNUMAЅб№№µД»щ±ѕ№№јЬЈ»ЅЪµгКЗ№№іЙNUMAПµНіµД»щ±ѕµҐФЄЈ¬ЛщОЅЅЪµгѕНКЗЦёѕаАлГїТ»ёцCPUѕЯУРПаН¬ѕаАлµДТ»Ж¬ґжґўЗшУтЈ¬ЅЪµгУЙCPUТФј°ПаУ¦µДHostbridgeєНґжґўПµНі№№іЙЈ¬ёГCPU¶ФУЪёГЅЪµгЦРµДґжґўЗшУтЦРµДГїТ»ёцЧЦЅЪѕЯУРПаН¬µД·ГОКИЁПЮЎЈНј1ЦРПФКѕБЛѕЯУР4ёцЅЪµгµДNUMA¶аґ¦АнЖчЅб№№Ј¬ГїёцЅЪµг·Ц±рУЙёчЧФµДHostbridgeёєФрЅЪµгДЪІїБ¬ЅУєНёчЅЪµгЦ®јдµДБЄПµЎЈ
---4ёцЅЪµгјґґжФЪ4ёцІ»Н¬µДКэѕЭґжґўЗшУтЈ¬NUMAЅб№№µД¶АМШЦ®ґ¦ѕНФЪУЪ¶ФУЪІ»Н¬ЗшУтµДґжґўЖчµД·ГОКИЁПЮЈ»ФЪSMPПµНіЦРЈ¬ёчёцґ¦АнЖч№ІПнН¬Т»їйґжґўЗшУтЈ¬ёчґ¦АнЖчИЁПЮПаН¬Ј¬ХвСщТІѕНФцјУБЛCPUјд¶Ф№ІПнДЪґжBUSµДѕєХщЈ¬ЅµµНБЛПµНіР§ВКЎЈNUMAЅб№№ЦРГїёцCPU¶јґшУР±ѕЅЪµгµД¶АБўДЪґжЈ¬CPUІ»µ«їЙТФ·ГОК±ѕµШДЪґж(Local Memory)»№їЙТФ·ГОКЖдЛыЅЪµгµДДЪґж(Remote Memory)Ј¬ХвСщІ»µ«јхЙЩБЛЧЬПЯѕєХщЈ¬Н¬К±МбёЯБЛґуИЭБїКэѕЭµДґжґўТЄЗуЎЈµ«КЗЈ¬ёчCPU¶Ф±ѕЅЪµгДЪґжѕЯУРУЕПИ·ГОКИЁПЮЈ¬¶ФЖдЛыЅЪµгµД·ГОКИЁПЮґОЦ®ЎЈ
1.2.2 NUMAЅб№№µДЕдЦГ
---NUMAЅб№№ЦРґжФЪ¶аёцЅЪµгЈ¬ІЩЧчПµНіФЪЅшРРµч¶ИµДК±єтКЗИзєОЗш·ЦёчЅЪµгµДCPUєНHstbridgeТФј°ґжґўЖчДШЈїФЪЦ§іЦNUMAПµНіµДЦч°еBIOSЦРґжФЪТ»¶О№М»ЇіМРтЈ¬ПµНіЖф¶ЇК±ёГіМРтФЛРРЈ¬ТФНкіЙ¶Ф°ьАЁДЪґжЎўCPUЎўHyperTransportЧЬПЯµИµДЕдЦГ№¤ЧчЈ»»бОЄГїТ»ёцCPUЎўMemoryЎўHostbridgeЦё¶ЁІ»Н¬µДIDЈ¬ТФ±гУЪІЩЧчПµНіµч¶ИєНУ¦УГіМРтК№УГЎЈГїёцЅЪµгµДHostbridgeЦРґжФЪИфёЙЎ°ґжґўПµНіЕдЦГјДґжЖчЎ±(Memory System Configuration Register),ГїёцјДґжЖчУГАґЕдЦГТ»ПоПµНіІОКэЎЈ°ґХХЖ书ДЬїЙТФ·ЦОЄ4АајДґжЖчЈє
---Function 0ЈєHyperTransport technology ConfigurationЈ»НЁ№эЙиЦГґЛАајДґжЖчїЙТФЦё¶ЁёГЅЪµгµДCPUµДIDТФј°HostbridgeµДIDЎЈ
--Function 1ЈєAddress map ConfigurationЈ» НЁ№эЙиЦГґЛАајДґжЖчїЙТФЙиЦГ±ѕЅЪµгµДMemoryµД·¶О§Ј¬ХвСщїЙТФКµПЦХыёцMemoryПµНіµШЦ·µДБ¬РшРФєН»ҐТмРФЎЈ
---Function 2ЈєDRAM ConfigurationЈ»НЁ№эґЛАајДґжЖчїЙТФЙиЦГёГЅЪµгµДDRAMµДМШРФЈ¬ИзИЭБїЎўАаРНЎўі§ЙМµИЎЈ
---Function 3ЈєMiscellaneous ConfigurationЈ»ЖдУ๦ДЬµДЕдЦГјДґжЖчЎЈ
---BIOSНЁ№э¶БРґБЅёцёЁЦъјДґжЖчАґКµПЦ¶ФґжґўПµНіЕдЦГјДґжЖчµД¶БРґЈ¬µЪТ»ёцёЁЦъјДґжЖчОЄЕдЦГµШЦ·јДґжЖч(Configuration Address Register)Ј¬НЁ№эґЛјДґжЖчАґСЎ¶ЁУы¶БРґґжґўПµНіЕдЦГјДґжЖчЈ»
---EnReg: ґжґўПµНіЕдЦГјДґжЖч·ГОКµДК№ДЬО»Ј»
---BusNumЈєЦё¶ЁЕдЦГµШЦ·µДЧЬПЯРтєЕЈ¬¶ФУЪДЪІїЅЪµгПµНі¶јОЄBus 0Ј¬¶ФУЪI/OНвЙиФтОЄBus 1Ј»
---DevNumЈєЦё¶ЁЕдЦГµШЦ·µДЙи±ёєЕЈ¬ЖдЦРД¬ИПЙи±ёєЕ24ЦБ31·Ц±р¶ФУ¦ЅЪµг0ЦБЅЪµг7Ј»
---FuncNumЈєЦё¶ЁЕдЦГјДґжЖчµД·ЦАаЧй±рЈ»
---RegNumЈєЦё¶ЁёГЧйЦРµДТ»ёцЕдЦГјДґжЖчЈ»
---ґЛµШЦ·ёЁЦъјДґжЖчµДµШЦ·ОЄ0CF8HЈ¬НЁ№эЙиЦГ±ѕјДґжЖчBIOSѕНСЎ¶ЁБЛТ»ёцУыЕдЦГµДґжґўПµНіЕдЦГјДґжЖчЈ¬И»єуЅ«ТЄРґИлёГЕдЦГјДґжЖчµДДЪИЭИзCPUµДIDµИ·ЕИлБнТ»ёцµШЦ·ОЄ0CF8HµДКэѕЭёЁЦъјДґжЖчЈ¬јґНкіЙБЛ¶ФЅЪµгµДЙиЦГЎЈ
1.2.3 ¶аґ¦АнЖчПµНіµДЖф¶Ї№эіМ
---NUMAЅб№№¶аґ¦АнЖчПµНіЦРЧЬУРТ»ёцCPUНЁ№эHyperTransport LinkБ¬ЅУµЅHyperTransport I/O Hub,ЦґРРЖф¶ЇК±Ј¬ґЛCPU±»іхКј»ЇІўЧчОЄBootstrap processor(Bsp)К№УГЈ¬¶шЖдУദАнЖч±»ЧчОЄApplication ProcessorК№УГЎЈBspґУДЪґжµШЦ·OXFFFFFFF0ґ¦їЄКјЦґРРЖф¶ЇіМРтЈ¬ПИєуНкіЙAPµДјмІвЎўHyperTransportЙи±ёµДіхКј»ЇЈ¬ґшїнєНЖµВКµДіхКј»ЇТФј°ЛщУРЅЪµгµДДЪґжїШЦЖЖчµДіхКј»ЇєНДЪґжµШЦ·µДіхКј»ЇЎЈФЪґЛ№эіМЦРЈ¬APµДЗлЗуОЮР§О»(Request diable bit)КЧПИ±»ЦГ1Ј¬APµДФЛРРЗлЗуОЮР§Ј»µИBspНкіЙБЛAPМЅІвИООсЦ®єуЅ«ёГО»ЗеБгЈ¬APѕНМшµЅOXFFFFFFF0ґ¦ЦґРРЖф¶ЇґъВлЈ¬Ц±ЦБХыёц¶аґ¦АнЖчПµНіЖф¶ЇНк±ПЎЈ
2 NUMA№№јЬЦРКµК±МШРФУ°ПмТтЛШ·ЦОц
2.1 ¶аґ¦АнЖчЅб№№¶ФУЪКµК±МШРФµДУ°Пм
---NUMAЅб№№ЦРЈ¬Т»ёцЅЪµгµДCPUІ»µ«їЙТФ·ГОК±ѕµШґжґўЖчЈ¬¶шЗТїЙТФ·ГОКО»УЪЖдЛыЅЪµгµДФ¶іМґжґўЖчЈ¬µ«КЗ·ГОКІ»Н¬ґжґўЖчµДК±јдІ»Н¬Ј¬ЛщТФіЖОЄ·ЗѕщФИґжґўЖч·ГОКПµНіЎЈИзНј1ЦРЛщКѕµД1Ўў2Ўў3ИэМхґжґўЖч·ГОКВ·ѕ¶Ј¬CPU¶ФУЪґжґўЖчµДїШЦЖТЄНЁ№эHostbridgeЦРµДДЪґжїШЦЖЖчАґНкіЙЈ¬И»¶шВ·ѕ¶µДі¤¶МёчТмЈ¬¶ФУЪФ¶іМЅЪµгµД·ГОКТЄНЁ№эІ»Н¬ЅЪµгµДHostbridgeЦ®јдµДНЁС¶АґКµПЦЈ»ЛщТФФЪNUMAЅб№№ЦРЈ¬µ±ЅЪµг1µДCPUТЄ·ГОКЅЪµг2»т3µДґжґўїХјдК±±ШРлНЁ№эЅЪµг2»т3µДHostbridgeАґНкіЙЈ¬µ±И»Уы·ГОКёьФ¶µДЅЪµг4µДґжґўїХјдЈ¬ёьТЄїзФЅБЅёцHostbridgeТФј°ПаУ¦µДЧЬПЯПµНіЈ¬ХвСщ±ШИ»»бґшАґТ»¶ЁµДСУК±ЎЈЛщТФЈ¬µ±КэѕЭ»тХЯіМРтґжґўФЪІ»Н¬µДДЪґжЗшУтК±Ј¬Жд¶БРґК±јдёчТмЈ¬ХвѕНКЗNUMAПµНі¶аґ¦АнЖчПµНі±ѕЙнёшПµНіКµК±МШРФґшАґµДУ°ПмЎЈ
2.2 УІјюјУЛЩ»ъЦЖµДУ°Пм
---ПЦґъґ¦АнЖч¶јІЙУГБЛУІјюјУЛЩ»ъЦЖАґЅшТ»ІЅјУїмПµНіФЛРРР§ВКЈ¬ХвР©»ъЦЖјУїмБЛКэѕЭєНіМРтµД¶БИЎЛЩВКЈ¬µ«КЗТІФцјУБЛТ»¶ЁµДІ»ОИ¶ЁТтЛШЈ¬ИзCacheЎўTLBЎўPipelineµИЈ¬ЖдЦРУ°ПмЧоґуµДКЗCacheЎЈCacheКЗО»УЪCPUУлДЪґжЦ®јдµДБЩК±ґжґўЖчЈ¬ИЭБїРЎУЪДڴ浫КэѕЭЅ»»»ЛЩ¶ИїмЈ¬CacheЦРµДКэѕЭКЗДЪґжЦРµДТ»Ії·ЦЈ¬КЗCPUѕіЈµчУГµДКэѕЭєНЦёБоЈ»IntelЅ«Cache·ЦіЙТ»ј¶»єґж(L1 Cache)єН¶юј¶»єґж(L2 Cache)Ј¬L1 CacheТ»°гјЇіЙФЪCPUЦРіЖОЄЖ¬ДЪCacheЈ¬Іў·ЦіЙI-CacheєНD-CacheЈ¬·Ц±рґж·ЕКэѕЭєНЦґРРХвР©КэѕЭµДГьБоЎЈCPU¶БИЎКэѕЭ»тЦёБоК±Ј¬ПИґУCacheЦРІйХТЈ¬Из№ыХТµЅѕНБўјґ¶БИЎёГКэѕЭ»тЦёБоІўЦґРРЦ®Ј¬ХвЦЦЗйїціЖОЄCache hitЈ»Па·ґЈ¬Из№ыФЪCacheЦРХТІ»µЅёГКэѕЭЈ¬ѕНУГПа¶ФВэµД¶аµДЛЩ¶ИґУДЪґжЦР¶БИЎЈ¬Н¬К±°СХвёцКэѕЭЛщФЪµДКэѕЭїйµчИлCacheЦРЈ¬їЙК№µГТФєу¶ФХыїйКэѕЭµД¶БИЎ¶јґУCacheЦРЅшРРЈ¬ТФМбёЯЛЩВКЎЈПФ¶шТЧјыЈ¬Cache hitК±µД·ГОКК±јдТЄГчПФµД¶МУЪCache missК±ЎЈ
---TLBКЗTranslation-Lookside BufferµДЛхРґЈ¬Паµ±УЪТ»ёцТіГжЧЄ»»µДCacheЈ»ФЪTLBЦРґжґўБЛЧоЅьґУРйДвµШЦ·µЅОпАнµШЦ·ЧЄ»»№эµДТі±нПо(Page table entry),ПµНіЅшРРµШЦ·ЧЄ»»К±»б¶ФЖдЅшРРЛСЛчЈ¬Из№ыёГ±нПоґжФЪУЪTLBЦРЈ¬ФтЦ±ЅУ¶БИЎЦ®Ј¬ИзІ»ФЩЈ¬Фт¶ФЖдЅшРРЧЄ»»ІўЅ«ЧЄ»»Ѕб№ыґжґўФЪTLBЦРЈ¬ЛщТФµ±TLBУРР§єНОЮР§К±»б¶ФПµНіµДФЛРРК±јдІъЙъТ»¶ЁµДУ°ПмЎЈ
---ЙПКцµДУ°ПмКЗПµНіУІјюЅб№№ґшАґµДЦчТЄУ°ПмЈ»µ±ІЩЧчПµНіФЛРРК±ТІ»б¶ФКµК±РФДЬІъЙъТ»¶ЁµДИнјюУ°ПмЈ¬ИзіМРтЙПЎўПВОДЗР»»µДК±јдЈ¬ЦР¶ПіМРтµчУГµДСУК±Ј¬ТФј°ПµНіФЛРРµч¶ИК±ІъЙъµДСУК±ЎЈ±ѕОДЦчТЄСРѕїУІјюЅб№№¶ФКµК±МШРФµДУ°ПмТФј°ПаУ¦µДІвКФ·Ѕ·ЁЎЈ
3 ІвКФ·Ѕ°ё
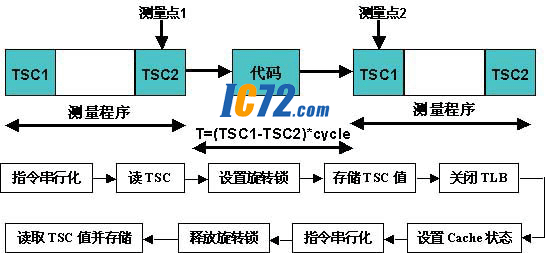
---Нј2ЦРПФКѕБЛКµК±МШРФІвКФ·Ѕ°ёТФј°ИнјюБчіМЈ¬ЖдЦРTSCКЗЎ°Time Stamp CounterЎ±µДЛхРґЈ¬AMDµДOpteronЦРМṩХвСщТ»ёц64О»УГАґјЗВјµ±З°µДК±ЦУЦЬЖЪКэЈ¬ЖдЦµіЛТФCPUµДК±ЦУЦЬЖЪјґОЄґ¦АнЖчЛщјЗВјµДµ±З°К±јдЈ»ГїґОґ¦АнЖчЖф¶ЇµДК±єтЅ«ЖдЗеБгЈ¬И»єуГїёцК±ЦУЦЬЖЪTSCµДЦµјУ1Ј¬ХвСщФЪТ»¶О№М¶ЁґъВлЦґРРЗ°єу·Ц±р¶БИЎTSCЦµ(ІвБїµг1Ўў2)јґїЙµГµЅґъВлЦґРРµДЦЬЖЪКэЈ¬ТФ±гК®·Цѕ«И·µШјЖЛгЖдґъВлЦґРРК±јдЈє
---T=(TSC1-TSC2)Ў¤cycle
---БнНвЈ¬ФЪІвКФіМРтЦРЙиЦГІвКФ»·ѕіµДёчЦЦІОКэЈ¬ИзНј2ЛщКѕµДІвКФіМРтЦґРРБчіМЎЈКЧПИЧцґ®РР»Їґ¦АнЈ¬±ЈЦ¤ґъВл°ґХХФКјЙијЖТвНј±»ЦґРРЈ¬·АЦ№УЙУЪPipelineµДґжФЪ¶шґтВТЦґРРЛіРтЈ»ЅУПВАґ¶БИЎTSCјДґжЖчµДЦµЈ¬И»єуЙиЦГSpinlockЈ¬јґОЄѕіЈУГµЅµДРэЧЄЛш№¦ДЬЈ¬ФڶദАнЖчПµНіЦРµ±Т»ёцCPUЦґРРТ»¶ОіМРтК±ІЙУГРэЧЄЛш№¦ДЬАґ·вЛшµ±З°ґъВлЈ¬·АЦ№±»ЖдЛыCPU¶БИЎІўёД¶ЇФміЙКэѕЭІ»Т»ЦВРФЈ»Лжєу¶БИЎTSCµДЦµЈ¬ІўК№TLBОЮР§ТФИ·±ЈCache¶ФУЪКµК±РФДЬµДО©Т»У°ПмЈ»Ц®єуЙиЦГCacheµДЧґМ¬Ј¬јґЗеїХCacheТФІъЙъCache missЧґМ¬Ј¬»тХЯІ»¶ФCacheЧцИОєОІЩЧчЈ¬±ЈЦ¤Cache hitµДїЙДЬРФЈ»ЛжєуЅшТ»ІЅЧцЦёБоґ®РР»ЇЈ¬ІўКН·ЕРэЧЄЛшЅвіэ±ѕґъВл¶ФЖдУദАнЖчµД·вЛшЈ»ЧоєујЗВјTSCµДЦµТФИ·¶Ёµ±З°К±јдЎЈ
---ёГІвКФФЪLinuxІЩЧчПµНіЦРНкіЙЈ¬Ѕ«ІвКФБчіМДЈїйІеИлLinuxДЪєЛЦРФЛРРТФМбёЯЖдУЕПИј¶єНІвКФѕ«И·РФЈ»Н¬К±Ѕ«ГїґОµДІвКФЅб№ыФЪУГ»§їХјд±ЈґжЖрАґЈ¬ІўУГLinuxЛщМбёЯµДgnuplot№¤ѕЯЅ«ЖдНјРО»ЇПФКѕіцИзНј3ЛщКѕµДНј±нЎЈ
4 ІвКФЅб№ы·ЦОц
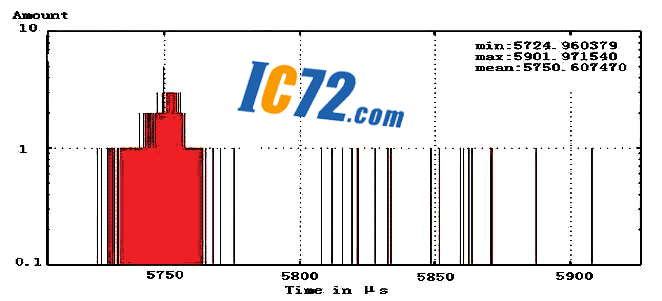
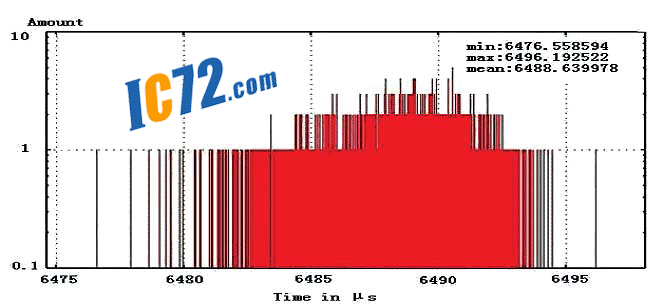
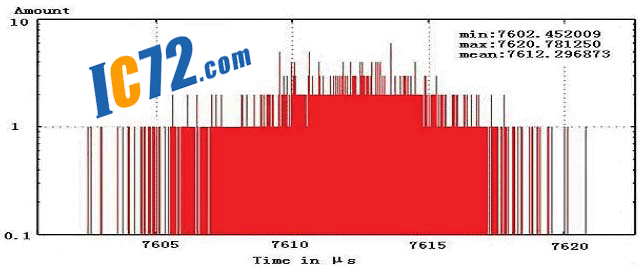
---Нј3.1Ўў3.2Ўў3.3·Ц±рПФКѕБЛ±ѕµШґжґўЖч·ГОКєНФ¶іМґжґўЖч·ГОКК±јдµДІвКФЅб№ыЈ»ЖдЦРИзНј1ЦРЛщКѕЈ¬СЎФсЅЪµг1ЧчОЄ±ѕµШЅЪµгЈ¬Ѕ«ЅЪµг1µДCPUј¤»оЈ¬ФтЖд¶ФУЪЅЪµг2Ўў3Ўў4µД·ГОКјґОЄФ¶іМґжґўЖч·ГОКЈ»ЖдЦРЈ¬ЅЪµг2Ўў3µДПа¶ФО»ЦГПаН¬Ј¬¶шЅЪµг4Фтґ¦УЪЧоФ¶¶ЛЈ¬¶ФЖдґжґўЖчµД·ГОКВ·ѕ¶Чоі¤ЎЈ
---КµСйЦРЈ¬ОТГЗІЙИЎБЛПтІ»Н¬ґжґўЗшУтРґИл10MПаН¬ґуРЎКэѕЭБїµД·Ѕ·ЁАґІвКФЖд·ГОКК±јдЈ¬Іў¶ФГїґОКµСйЧц4000ґОЦШёґТФНіјЖЖдЅб№ыЎЈПФ¶шТЧјыЈ¬±ѕµШґжґўЗшУтµД·ГОКК±јдЧо¶МЈ¬ЖЅѕщОЄ5750.6¦МsЈ»¶ш¶ФУЪФ¶іМґжґўЗшУтµД·ГОКФтєДК±ЅПі¤Ј¬ЖдЦРЅЪµг2Ўў3µД·ГОКК±јдЖЅѕщґп6488.6¦МsЈ¬¶шЧоФ¶µДґжґўЗшУт·ГОКК±јдёьі¤Ј¬ґп7612.3¦МsЈ¬ХвР©Ѕб№ыПФКѕБЛNUMAЅб№№¶аґ¦АнЖчПµНі±ѕЙн№№јЬ¶ФУЪПµНіКµК±МШРФµДУ°ПмЎЈБнНвЈ¬ОТГЗФЪ±ѕµШґжґўЗшУтµД·ГОКК±јдІвКФК±Ј¬їјВЗБЛCache¶ФУЪПµНіПмУ¦К±јдµДУ°ПмЈ»їЙТФїґµЅЈ¬ґуІї·ЦЅПРЎµДІвКФЅб№ы±ИЅПјЇЦРЈ¬О»УЪ5750¦МsЧуУТЈ¬Хв±нКѕCPUЦ±ЅУґУCacheЦР¶БИЎКэѕЭ(Cache hit)К±µДПмУ¦ЛЩ¶ИЅПїмЈ»¶шБнНвТ»РЎІї·Ц·ЦЙўµДІвКФЅб№ыПФКѕБЛCacheЦРІ»ґжФЪCPUТЄЗуµДКэѕЭЈ¬ЧЄ¶шґУЦчґжЦР¶БИЎКэѕЭ(Cache miss)µДПмУ¦К±јдЎЈ
---НЁ№э±ѕВЫОДµДКµСйЈ¬ОТГЗїЙТФїґіцNUMAЅб№№¶аґ¦АнЖчПµНіНкИ«їЙТФККУ¦КµК±ИООсµДТЄЗ󣬵«КЗІ»Н¬ЗйїцПВЖдПмУ¦К±јдТІІ»ѕЎПаН¬ЎЈКµјКµДКµК±ИООсЖдґъВл¶јЅПРЎЈ¬Т»°гЗйїц¶јКЗїШЦЖёчЦЦїШЦЖПµНіµДЦЬЖЪїЄ№ШБїЈ»ЛщТФµ±NUMAЅб№№УГУЪКµК±ПµНіЦРК±ЧоїЖС§µД°м·ЁКЗЈ¬Зш·Цёчёцґ¦АнЖчµД№¦ДЬЈ¬Ѕ«Жд·ЦОЄФЛРРНЁУГІЩЧчПµНіИзLinuxµДґ¦АнЖчТФј°ФЛРРКµК±ЅшіМµДґ¦АнЖчЎЈИ»єуЈ¬Ѕ«КµК±ЅшіМµДЦґРРґъВлЛшґжФЪКµК±ґ¦АнЖчµДCacheЦРЈ¬ХвСщ±ШИ»»бИЎµГЧоєГµДКµК±Р§№ыЈ¬ЅшТ»ІЅЛх¶МПмУ¦К±јдЈ¬ёьєГµШВъЧгПµНіµДКµК±ТЄЗуЎЈ
5 ЅбКшУп
---ЛжЧЕїШЦЖѕ«¶ИєНёґФУРФµДІ»¶ПМбёЯЈ¬¶ФУЪПµНіКµК±МШРФµДТЄЗуіЙОЄ±ШИ»ЗчКЖЎЈНЁУГјЖЛг»ъПµНіТФЖдµНБ®µДјЫёсєНЅПєГµДЖЅѕщ№¦ВК¶ш±»№г·єУ¦УГУЪёчёцКµК±БмУтЎЈNUMAЅб№№¶аґ¦АнЖчПµНіТФЖдЅЪµгїЙА©Х№РФЈ¬ЅшТ»ІЅМбёЯБЛПµНіµДРФДЬЈ¬їЄНШБ˶ദАнЖчПµНіРВµД·ўХ№·ЅПтЈ»Н¬К±µ±NUMAЅб№№¶аґ¦АнЖчПµНіУ¦УГУЪКµК±ПµНіЦРК±Ј¬ТІІ»їЙ±ЬГвµШ»б¶ФПµНіµДКµК±МШРФФміЙТ»¶ЁµДУ°ПмЎЈ±ѕОДНЁ№эКµСй·ЦОцБЛNUMAМеПµЅб№№¶ФУЪПµНіКµК±МШРФµДУ°ПмЎЈ