у╙р╙ё╨╠╬нджВр╙ҐИиэҐЭдЙюЄЁЖож╣дҐБ╬ЖЄіюМфВ╨мЄФЄ╒фВж╝╪ДкыІх╡НрЛ╣др╩п╘пбЇҐЇ╗ё╛хГPIM║╒цФоРйЩ╬щаВ╣д╦ъптдэ╪фкЦ╨м╣ьжЇя╧кУ╣х║ё
╧ь╪ЭЄйё╨ЄіюМфВё╩ЄФЄ╒фВё╩PIMйЩ╬щаВё╩╦ъптдэ╪фкЦё╩╣ьжЇя╧кУ
рЩят
ЄФЄ╒фВтзо╣мЁжп╟Гящ╣дҐги╚йгЄФЄ╒CPU╧євВкЫпХ╣д╨мфД╡ЗиЗ╣дкЫспйЩ╬щ║ёр╩╦ЖюМоК╣дЄФЄ╒о╣мЁдэ╧╩Ґ╚CPUкЫпХр╙╣дйЩ╬ща╒╪ЄлА╧╘╦ЬкЭё╛╣╚уБҐЖҐЖйгр╩╦ЖюМоК╣дЄФЄ╒о╣мЁІЬряё╛р╙оКй╣ожуБ╦Жд©╠Ййг╡╩ЇШ╨ой╣╪й╣д║ёЄФЄ╒фВ╣дхЩр╙кьё╗хща©║╒кыІх╨мЄЗ╪шё╘ж╝╪ДйгоЮ╩╔Іта╒╣д║ёкЫртЁєфзртюЄё╛сісцвН╧ЦЇ╨╣дҐБ╬ЖЇҐЇ╗╬мйгЄФЄ╒фВ╡ЦЄн╩╞║ёкЭкЫюШсц╣дтґюМ╬мйг╬ж╡©пттґюМё╨й╠╪Д╬ж╡©пт╨м©у╪Д╬ж╡©пттґюМ║ёЄФЄ╒фВ╟Єуу╡ЦЄнсиио╣Ґоб╣дкЁпРфДхща©тҐюЄтҐЄСё╛кыІхтҐюЄтҐбЩё╛╣╔н╩хща©ЄЗ╪штҐюЄтҐп║║ёЄФЄ╒фВ╡ЦЄн╩╞╣дд©╠ЙйглА╧╘р╩╦ЖЄЗ╪шоЯвН╣м╡ЦЄн╣дЄФЄ╒фВр╩яЫ╣мІЬкыІхоЯвН╦ъ╡ЦЄн╣дЄФЄ╒фВр╩яЫ©Л╣дЄФЄ╒о╣мЁ║ё╣╠г╟╣дЄФЄ╒о╣мЁр╩╟ЦІ╪╩╝Їжн╙ртоб╪╦╦Ж╡ЦЄнё╨
ё╗1ё╘╪дЄФфВ
хща©вНп║║╒кыІхвН©Л╣дЄФЄ╒фВё╛кЭн╩сзCPUжпё╛фД╧эюМйгси╠ЮрКфВюЄмЙЁи║ё╠ЮрКфВ╬ЖІ╗тзЁлпРжЄпп╣ддЁр╩╣Цр╙Ґ╚ддп╘йЩ╬щЄФЄ╒тз╪дЄФфВжп║ё
ё╗2ё╘Cache
хща©Ґоп║║╒кыІхҐо©Л╣д©©ҐЭЄіюМфВ╣д╦ъкыЄФЄ╒фВё╛кЭм╗ЁёйгсиSRAMвИЁиё╛сцюЄЄФЄ╒ЄіюМфВвНЁёсц╣дйЩ╬щ║ёр╩╣╘Ї╒иЗCache╡╩цЭжпё╛ЄіюМфВ╬мр╙Єсобр╩╡ЦЄн╣дЄФЄ╒фВжпІах║кЫпХ╣дйЩ╬щ║ёCacheр╡©иртҐЬпп╡ЦЄн╩╞вИж╞║ё
ё╗3ё╘жВЄФЄ╒фВ
Cache╣добр╩╡ЦйгжВЄФЄ╒фВё╛кЭр╩╟ЦйгсиDRAMвИЁиё╛фДхща©р╙╠хCacheЄСё╛╣╚ЄФх║кыІхр╙╠хCacheбЩ║ё
ё╗4ё╘╦╗ЄФЄ╒фВ
уБйгн╩сзЄФЄ╒фВ╡ЦЄнжпвН╣м╡ЦЄн╣дЄФЄ╒фВё╛уШ╦Жо╣мЁжп╬ЬЄС╡©Їж╣дйЩ╬щЄФЄ╒тзуБюО║ё
ЄіюМфВ╨мЄФЄ╒фВптдэ╡Н╬Ю╣д╡ЗиЗ
Єс╟К╣╪лЕ╧єру╣дЇ╒у╧гВйфюЄ©Єё╛ЄіюМфВптдэ╦диф╣дкыІхтІтІЁ╛╧ЩЄФЄ╒фВптдэ╣д╦диф║ё╣╪жбЄіюМфВ╨мЄФЄ╒фВптдэ╡Н╬Ю]╣дтЖЁєспІЮжжтґрРё╛╟К╣╪лЕ╧єруЇжн╙ЄіюМфВ╧єру╨мЄФЄ╒фВ╧єруаҐ╦ЖуСс╙ё╛гр╡исц╡╩м╛╪╪йУё╛уБ╣╪жбаккЭцгж╝╪Дптдэ╡Н╬Ю╡╩ІотЖЄС║ёфДжпё╛ЄіюМфВптдэц©дЙ©илА╦ъ60%вСсрё╛ІЬЄФЄ╒фВЄФх║й╠╪Д╣д╦дифц©дЙ╡╩╣Ґ10%║ё
фю╪шптдэ╣д╠Йв╪
╪фкЦ╩Зо╣мЁ╣дптдэсКфДжЄппй╠╪Дж╠ҐсоЮ╧ьё╛обап╠МЄОйҐ╦ЬЁЖакжЄппй╠╪Д╣д╠Мй╬ЇҐЇ╗ё╨
TCPU=IC║аCPI║аPeriodCLOCK
уБюОICн╙кЫр╙жЄпп╣дж╦аНйЩё╛CPIн╙жЄппц©лУж╦аНкЫпХ╣дй╠жсйЩё╛PeriodCLOCKн╙й╠жсжэфз║ё╪фкЦ╩Зптдэх║╬ЖсзЄіюМфВ╨мЄФЄ╒фВж╝╪Д╣дҐс©зё╛хГ╧ШҐс©з╡╩йй╬м╩Ай╧CPIтЖЄСЄсІЬй╧╣цCPU╪фкЦй╠╪ДтЖ╪с║ёаМмБр╩╦Ж©ирт╨Ба©иоцФкЫк╣╣д╦ВоНж╦╠Й╬мйгЄФЄ╒фВфҐ╬ЫЄФх║й╠╪Д║ё
TACCESS=THIT+RMISS║аTMISS
уБюОTHITн╙ЄФЄ╒фВЇцнйцЭжпй╠╣дЄФх║й╠╪Дё╛RMISSн╙ЄФЄ╒фВЇцнй╡╩цЭжп╣д╠хюЩё╛TMISSн╙Ї╒иЗЄФЄ╒фВЇцнй╡╩цЭжпй╠╣дЄФх║й╠╪Д║ё
╦дифптдэ╡Н╬Ю╣дЇҐЇ╗
Є╚мЁ╣дҐБ╬ЖЇҐЇ╗
╟К╣╪лЕ╧єру╣длА╦ъй╧╣цртг╟р╩п╘Є╚мЁ╣дҐБ╬ЖЇҐЇ╗ЁйожЁЖр╩п╘иЗ╩Зё╛обцФҐИиэр╩п╘Є╚мЁ╣дЇҐЇ╗║ё
ё╗1ё╘й╧сц╦ЭІЮ╣дф╛иоCache
й╧сц╦ЭІЮ╣дCache©ирт╪Уиым╗╧Щ╩╔а╛мЬбГоРн╩сз╣м╡ЦЄн╣дЄФЄ╒фВҐЬппЄФх║╣дЄнйЩё╛кФве╟К╣╪лЕ╧єру╣длА╦ъожтзп╬ф╛ио╣дCacheхща©©иртвЖ╣д╠хҐоЄС║ё╣╚йгё╛╬║╧эожтз╣дCache╣дхща©ря╬ґЄО╣Ґакув╪Іё╛©иртЄФЄ╒ЄС╡©Їжсісц╣д╪Єй╠йЩ╬щ╪╞ё╛╣╚йгвэспр╩п╘сісц╣дйЩ╬щ╡╩дэмЙх╚ЇетзCacheжпё╛╠ххГЇж╡╪йЩ╬щсісц╨мдЁп╘ЄС╧Фдё╣дсісц║ё
ё╗2ё╘м╗╧Щ╩ЫжЇ╪дЄФфВCacheҐЬпп╣ьжЇя╧кУ
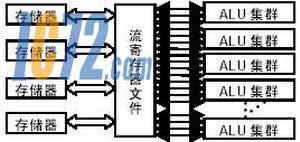
сисзожтз╣дЄФЄ╒©у╪Д╡╩Іою╘ЄСІЬй╧╣ц╣ьжЇ©у╪Др╡╡╩ІотЖЄСё╛пХр╙тҐюЄтҐІЮ╣д╣ьжЇоъсцюЄтзЄіюМфВ╨мЄФЄ╒фВж╝╪ДЄ╚йД╣ьжЇпео╒ё╛уБп╘╣ьжЇпео╒аВ╬ъсп╨эЄСЁлІхио╣дтщй╠пт╨м©у╪Д╬ж╡©пт║ёрРЄкё╛р╡╬м╬ъспр╩І╗╣д©итє╪Шпт║ётзр╩╦Ж╣ьжЇвжІнжпж╩сп╨эиы╣ддзхщйгсппї╣дё╛рРЄк©иртҐ╚╣ьжЇ╣д╦ън╩пео╒ЄФЄ╒╣ҐІ╞л╛ЇжеД╣д╩ЫжЇ╪дЄФфВжпё╛╡╒пнЁир╩╦Ж╣ьжЇкВрЩ╠М║ётзҐЬпп╣ьжЇпео╒Є╚йДй╠ж╩Є╚йД╣ьжЇ╣д╣мн╩вжІн╨м╦ън╩вжІн╣дкВрЩё╛ІЬ╡╩╠ьЄ╚йДуШ╦Ж╣ьжЇпео╒ё╛ЄсІЬсппїлА╦ъЄіюМфВ╣дсппїЄЬ©М║ё
ё╗3ё╘й╧сц╦Э©Л╨м╦Э©М╣дЄФЄ╒фВвэоъ
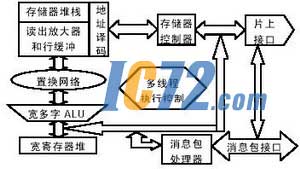
уБр╡йгр╩жжвН╩Ы╠╬╣дЇҐЇ╗ё╛сисзЄФЄ╒фВЄЬ©М╬мйгц©цКжсЄ╚йД╣дйЩ╬щвэа©ё╛рРЄк©иртм╗╧ЩлА╦ъо╣мЁй╠жсё╗╪Уп║ЄФх║й╠╪Дё╘╨мтЖ╪сЄФЄ╒фВвэоъ╣д©МІхюЄтЖ╪сЄФЄ╒фВЄЬ©М║ёх╩ІЬІтсзд©г╟╣дDRAMюЄк╣ё╛уБп╘ЇҐЇ╗ря╬ґЄО╣ҐаккЭ╣дй╣╪йҐГоч║ё╦Э╦ъф╣бй╣дй╠жс╬мр╙гСо╣мЁ╣дй╠пРр╙гС╦Э╪сяо╦Яё╛ЄсІЬ╬мпХр╙╦Э╪с╬╚хЇ╣д╡©╪Чё╛уБр╡╦ЬPCB╣дЁипмЄЬюЄпМІЮюїдяё╩тЖ╪сЄФЄ╒фВвэоъ╣д©МІх╬мр╙тЖ╪сп╬ф╛рЩҐейЩд©╨мI/O╣д╧і╨дё╛м╛яЫр╡╩А╦ЬPCB╣д╡╪╬жЄЬюЄ╠хҐоЄС╣ддяІх║ё╬║╧эожтз╣дЄФЄ╒фВЇБв╟╧єруря╬ґ©иртсіІтп╬ф╛рЩҐейЩд©╣д╡╩ІотЖ╪сё╛╣╚йгсисз╧і╨д╨мЄЗ╪ш╣дтґрРй╧╣цп╬ф╛рЩҐейЩ╡╩╩АкФвеЄіюМфВкыІх╣дтЖ╪сІЬ╡╩ІотЖ╪с║ё
р╩п╘пбЇҐЇ╗
ҐЭдЙюЄё╛р╣ҐГуКІтЄРффЇК║єе╣рюбЭҐА╧╧Іто╣мЁптдэ╣дочжфІЬлАЁЖакпбЇҐЇ╗ё╛жВр╙спртобаҐжж║ё
ё╗1ё╘PIMё╗Processor-In-Memoryё╘
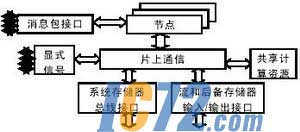
PIMҐА╧╧м╗╧ЩҐ╚ЄФЄ╒фВ╨мЄіюМфВ╪╞Ёи╣Ґм╛р╩©Ип╬ф╛иоЄсІЬ╠эцБактзЄ╚мЁ╪фкЦ╩Зо╣мЁжп╣дЇК║єе╣рюбЭҐА╧╧╣дф©╬╠║ём╪1╦ЬЁЖакр╩╦ЖPIMҐА╧╧╣дMINDп╬ф╛╣дй╬рБм╪ё╛©иртм╗╧ЩІЮжж╩╔а╛ҐА╧╧Ґ╚уБжжп╬ф╛а╛ҐсЁиҐоЄС╣до╣мЁ║ё